📘 전통 정치학 기능과 LLM이 불러온 혁신
정치학에서 오랫동안 사용되어온 분석 방식들은 기본적으로 통계 분석, 설문조사, 사례 연구 등을 중심으로 발전해왔습니다. 하지만 LLM(대규모 언어 모델)이 도입되면서 이 분야에 큰 전환점이 찾아왔습니다. 이 논문에서는 LLM이 정치학 연구에 어떤 방식으로 응용되고 있는지를 다섯 가지 영역으로 정리했습니다. 네 가지는 기능적 활용(ex: 예측, 생성, 시뮬레이션, 인과분석)이고, 마지막 하나는 윤리적·사회적 함의에 대한 고찰입니다.
🔮 예측(Predictive) 작업의 자동화: 정치학 연구의 새 전환점
정치학 연구에서 "앞으로 무엇이 일어날 것인가?"를 예측하는 일은 오래전부터 중심 과제였습니다. 선거 결과 예측, 정책 반응 분석, 여론 변화 탐지 등은 학계뿐 아니라 정부, 언론, 싱크탱크에서 매우 중요한 작업입니다. 기존에는 이 모든 작업이 사람 손으로 데이터를 수집하고 정제하며 분석해야 했습니다. 그런데 지금, **LLM(대규모 언어모델)**이 이 과정 전반을 자동화하면서 정치학 연구의 패러다임이 바뀌고 있습니다.
🧠 예측 작업이란?
논문에서는 예측 작업(predictive tasks)을 미래의 사건이나 경향을 기존 데이터에 기반하여 추론하는 작업이라고 정의합니다. 예를 들면:
- 다음 선거에서 누가 이길 것인가?
- 이 정책 발표 이후, 여론은 어떻게 움직일 것인가?
- 특정 정당 지지층은 어떤 이슈에 민감하게 반응하는가?
이처럼 예측은 단순한 '결과 알아맞히기'가 아니라, 복잡한 정치사회적 변수들을 고려하여 정치 행동과 반응을 사전에 이해하려는 시도입니다.
⚙️ 기존 방식의 한계: 느리고, 비싸고, 주관적이다
정치학에서 예측을 위해 데이터를 분석하는 작업은 대개 전통적인 연구 설계와 수작업 중심의 접근에 의존해왔습니다. 겉보기에는 단순한 선거 예측처럼 보여도, 실제 그 과정은 매우 복잡하고 노동 집약적이었습니다. 다음과 같은 문제들이 반복적으로 제기되었습니다:
1. 데이터 수집이 느리다
- 대부분의 예측 연구는 설문조사, 인터뷰, 텍스트 수집 등 사람이 직접 데이터를 모으는 과정에 기반합니다.
- 예를 들어 여론의 이념 성향을 파악하려면 전국적으로 설문지를 배포하고, 수백 혹은 수천 명의 응답을 수집한 뒤 수작업으로 정리해야 합니다.
- 결과적으로 데이터 수집과 전처리에만 수주에서 수개월이 걸리는 일이 다반사였습니다.
2. 분석 비용이 많이 든다
- 설문조사에 드는 비용, 데이터 정제에 필요한 인건비, 라벨링을 위한 연구보조원까지, 정치학 연구의 예측 파이프라인은 매우 고비용입니다.
- 특히 감성분석이나 정책입장 분석처럼 텍스트 데이터를 처리해야 하는 경우, 연구자는 수천 개 문서를 직접 읽거나 코더(coders) 팀을 구성해야 했습니다.
- 이 과정에서 발생하는 인건비와 시간 낭비는 정치학 연구의 확장성과 지속가능성을 위협했습니다.
3. 코딩의 일관성이 부족하다
- 정치학 텍스트 코딩은 고도로 주관적인 작업입니다.
예를 들어, “이민은 우리 경제에 위협이다”라는 문장을 한 코더는 강한 보수 이념으로, 다른 코더는 단순한 정책 우려로 판단할 수 있습니다. - 연구보조원 간 라벨링 일관성을 유지하려면 복잡한 코드북 작성과 사전 교육이 필요하고, 그마저도 라벨 간 불일치(inter-coder disagreement) 문제는 완전히 해결되지 않습니다.
- 결과적으로 데이터의 신뢰성과 재현 가능성(replicability)이 떨어지고, 연구 결과가 연구자의 주관에 너무 의존하게 되는 문제가 발생합니다.
🤖 LLM으로 자동화된 예측: 바뀌는 패러다임
LLM의 등장은 이 모든 고질적인 문제들을 근본적으로 바꾸고 있습니다. 단순히 ‘더 빠르고 싸게 한다’는 수준을 넘어서, 정치학 연구의 구조 자체를 재설계할 수 있게 해주고 있습니다.
1. 속도와 규모에서 압도적 우위
- LLM은 대규모 텍스트 데이터를 거의 실시간으로 처리합니다.
예를 들어 수천 건의 뉴스 기사나 유권자 댓글, 정치 연설문도 몇 분 안에 분석하고 분류할 수 있습니다. - 기존 수작업과 비교했을 때, 수백 배의 속도와 무한에 가까운 확장성을 보입니다.
실제로 Claude, GPT-4, Llama 같은 모델은 정치학자들이 다룰 수 없었던 수준의 대규모 데이터셋도 자유롭게 다룹니다.
2. 정치 텍스트 라벨링의 자동화
- 전통적으로 라벨링이 필요했던 정치 텍스트들(정당 입장문, 공약, 여론조사 응답 등)에 대해, LLM은 사람보다 더 일관된 기준으로 자동 라벨링이 가능합니다.
- 논문에서는 감정(sentiment), 이념성향(ideology), 정책 분야(relevance), 부정성(negativity) 등을 대상으로 수많은 자동 라벨링 연구를 소개합니다.
- 특히 GPT-4의 라벨링은 크라우드 워커보다 우수, 때로는 전문가 수준에 필적하는 정밀도를 보였다고 평가됩니다. (Heseltine et al 2024; Mellon et al 2024)
3. 정치적 맥락 이해까지 확장
- 기존의 예측 모델은 수치 기반이었기 때문에 텍스트의 의미나 맥락을 파악하기 어려웠습니다. 반면 LLM은 자연어를 처리할 수 있기 때문에, 문장 안에 숨겨진 정치적 의도, 이념적 암시, 감정적 뉘앙스까지 파악합니다.
- 예컨대 “이민 정책은 신중해야 한다”와 “불법 이민은 반드시 차단해야 한다”는 두 문장은 다르게 해석되어야 하는데, LLM은 이를 분리해내는 데 탁월합니다.
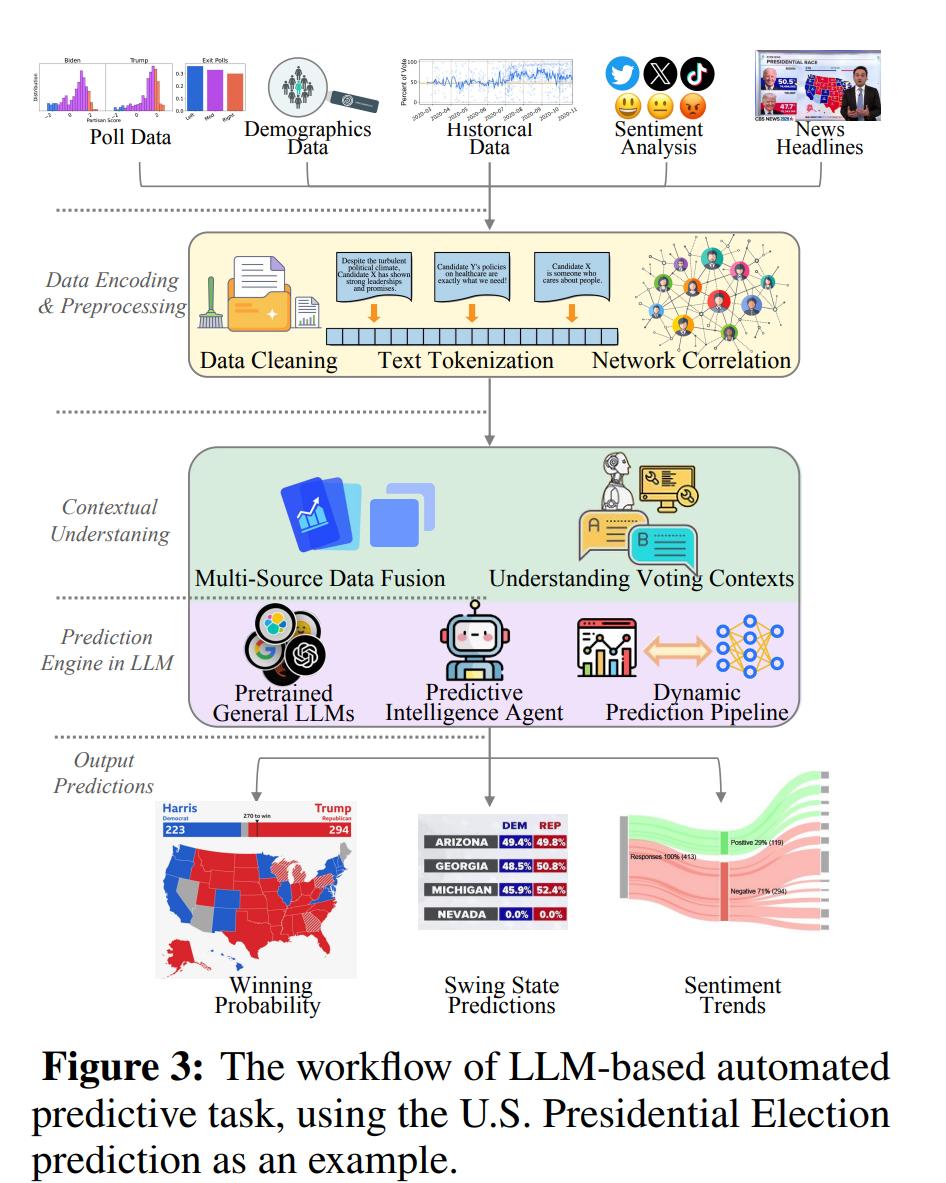
4. 예측에 필요한 전체 파이프라인 통합 가능
- Figure 3에서는 미국 대선 예측의 자동화 전체 과정이 그려져 있습니다.
이 흐름은 단순 라벨링을 넘어, LLM이 다양한 데이터를 통합해서 실제 예측값(예: swing state 승부 예측, 후보 당선 확률 등)을 산출하는 능력을 시각화한 것입니다. - 데이터 수집 → 전처리 → 맥락이해 → 결과 생성까지의 완전 자동화된 파이프라인이 LLM으로 현실화되고 있는 것입니다.
- 📊 Figure 3 예시: 미국 대선 예측 자동화
- 다양한 데이터 소스 통합: 여론조사 결과, 인구통계 정보, 뉴스 헤드라인, 트위터 등
- 전처리: 데이터 정제, 토큰화, 벡터화
- 문맥 이해: LLM이 맥락을 파악하고 정치적 상관관계를 학습
- 예측 출력: 승부처 주(state-level swing prediction), 후보별 당선 확률 추정 등
- 이 도식은 다음의 순서를 보여줍니다:
🌍 다국어/비영어권에서도 활용 가능성 확인
LLM은 원래 영어 기반의 대규모 웹 텍스트를 중심으로 학습되었기 때문에, 영어 중심적 성능에 대한 우려가 많았습니다. 하지만 최근 연구들은 LLM이 비영어권에서도 실제 정치 데이터를 안정적으로 처리할 수 있다는 점을 보여주고 있습니다. 이는 특히 비교정치나 지역연구를 하는 학자들에게 매우 중요한 발전입니다.
✅ GPT-4의 다국적 정치 텍스트 코딩 실험 [33]
- GPT-4는 미국, 독일, 이탈리아, 칠레 등 다양한 언어 환경의 정치 텍스트를 대상으로 실험되었습니다.
- 텍스트 유형은 국회의원 발언, 정당 성명서, 언론 기사 등이며, 평가 기준은 다음과 같은 변수들입니다:
- 정치적 관련성(relevance)
- 부정성(negativity)
- 감정(sentiment)
- 이념 성향(ideology)
그 결과 GPT-4의 코딩은 전문가의 수작업 라벨링과 유사하거나 높은 수준의 정합성을 보였으며, 특히 이념 성향 측정에서는 일관성이 매우 우수한 것으로 나타났습니다.
✅ LLaMA를 활용한 유럽의회 연설 분석 [131]
- 이 연구에서는 Meta의 LLaMA 모델을 사용해 유럽의회에서 진행된 공식 연설들을 분석했습니다.
- LLM의 정치적 맥락 이해도를 검증하기 위해, 유럽 정당들의 공식 입장을 정리한 EUandI 설문을 기준으로 삼았습니다.
결과는 흥미로웠습니다. LLaMA는 특정 정당의 입장 정렬(alignment), 연설의 이념적 색채, 정책 우선순위 등을 정확히 판단해냈습니다. 심지어 GPT-4와 유사한 수준의 **문맥 기반 추론 능력(contextual reasoning)**도 확인되었습니다.
✅ Claude-1.3의 자유 응답식 설문 분류 [146]
- 영국의 British Election Study Internet Panel은 유권자들에게 “당신이 생각하는 가장 중요한 이슈는 무엇인가요?”라고 묻는 자유 응답형(free-text) 질문을 사용합니다.
- Claude-1.3 모델은 이 텍스트 응답들을 50개 이슈 카테고리로 자동 분류했습니다.
사람이 일일이 코딩하면 수개월이 걸릴 작업이지만, Claude는 수십만 개의 응답을 몇 시간 만에 처리했습니다. 결과의 정확도와 신뢰도 역시 인간 코더와 유사하거나 더 나은 경우도 있었으며, 특히 다의적이고 모호한 응답에 대해서도 상당히 정교한 판단을 보여주었습니다.
💡 핵심 요점: LLM은 영어권을 넘어 다양한 언어와 정치적 맥락에서도 비교적 높은 성능을 보여주고 있으며, 이는 비영어권 정치 연구자에게도 실제적인 도구가 될 수 있음을 입증하고 있습니다. 앞으로 더 다양한 언어와 지역 데이터셋에서의 벤치마킹이 계속된다면, 정치 데이터 분석의 세계적 표준으로 자리잡을 수 있습니다.
🛠 맞춤형 프레임워크의 등장
LLM이 강력하다고는 해도, 그 자체로 정치학 연구에 바로 적용되는 경우는 드뭅니다. 정치 담론은 문맥에 따라 해석이 달라지고, 표현 방식도 다양하기 때문에, 일반적인 LLM만으로는 정확한 분석이 어려운 경우도 많습니다. 이에 따라 최근에는 정치학 연구에 특화된 LLM 응용 프레임워크들이 등장하고 있습니다.
✅ PoliPrompt: 정치텍스트 분류를 위한 3단계 LLM 프레임워크 [68]
PoliPrompt는 뉴스 기사, 캠페인 광고, 정당 논평 같은 정치 문서를 정교하게 분류하기 위한 구조화된 프레임워크입니다. 세 가지 단계로 구성됩니다:
- 사전 분류(Prompt Filtering): LLM이 텍스트의 범주를 크게 나눌 수 있도록 유도하는 필터링 질문을 먼저 설정
- 이슈 분류(Task-specific Prompting): 분류하고자 하는 정치적 주제에 특화된 질문을 구성
- 어조 및 이념 분석(Tone & Ideology Prompting): 감정/이념과 같은 라벨을 정확히 추출할 수 있도록 미세 조정
결과적으로 PoliPrompt는 다중 범주의 정치 문서를 처리할 때 높은 분류 정확도와 일관성을 보여주며, BBC 뉴스, 선거 광고 분석 등 실제 데이터셋에서 탁월한 성능을 입증했습니다.
✅ ParlVote+ 벤치마크에서의 메타데이터 통합 [132]
- 기존 연구는 정치 입장 분류에서 단순히 텍스트 정보만 활용했지만, 이 연구는 정당, 선거 연도, 발언자 정보 등 메타데이터를 통합했습니다.
- 예를 들어, 동일한 발언이더라도 “보수당 의원이 말했다”는 정보가 있으면 맥락 해석이 완전히 달라집니다.
이처럼 정치적 맥락을 풍부하게 반영한 프롬프트 구조를 설계함으로써, LLM의 정치 입장 분류 성능이 크게 향상되었습니다. 이 접근법은 특히 의회 회의록, 정당 토론, 정책 입장 분석에서 높은 정확도를 기대할 수 있습니다.
🎯 요약
- LLM은 영어권을 넘어서 다양한 언어권과 지역의 정치 텍스트를 안정적으로 분석할 수 있는 수준에 도달하고 있으며, 이는 비교정치나 지역정치 연구에서 매우 중요한 가능성을 보여줍니다.
- 동시에, 정치학 연구에 맞춘 프롬프트 설계와 분석 프레임워크 개발이 활발하게 진행 중입니다. 단순히 모델을 호출하는 것을 넘어서, 연구 목적과 문맥에 맞는 맞춤형 설계가 LLM의 효율성과 정확도를 결정짓습니다.
⚠️ 한계와 과제
물론 한계도 존재합니다.
- 미묘한 정치적 문맥을 오해할 수 있습니다. 예컨대, 풍자나 반어를 진지한 발언으로 인식할 수 있음
- 비주류 언어권에서는 데이터 부족으로 성능이 떨어질 수 있음
- 학습 데이터 자체의 편향(예: 진보 성향 미디어가 많은 경우)으로 인해 예측 결과가 한쪽으로 쏠릴 수 있음
- 도메인 전문성 부족: 아주 특수한 정책 맥락에서는 아직 인간 전문가보다 이해력이 떨어지는 경우도 있음
따라서 LLM을 쓸 때는 반드시 정치학적 해석과 점검이 병행되어야 하며, 후속 검증 절차도 필수입니다.
🤖 4.3 LLM 시뮬레이션 에이전트: 정치학을 위한 새로운 실험실
정치학에서 전통적으로 사용되던 행위자 기반 모델(Agent-Based Models, ABMs)은 정해진 규칙과 시나리오 안에서 에이전트(agent)의 행동을 설정한 뒤, 그들의 상호작용을 관찰하는 방식이었습니다. 하지만 이 방식은 현실 정치의 복잡하고 유동적인 상황을 충분히 반영하기에는 한계가 있었습니다. 여기에 **LLM(대규모 언어모델)**이 들어오면서, 정치학 연구자들은 완전히 새로운 차원의 ‘시뮬레이션 정치 실험실’을 만들 수 있게 된 것입니다.
🔍 시뮬레이션 에이전트란?
- **시뮬레이션 에이전트(Simulation Agents)**는 LLM을 기반으로 하여, 실제 인간 정치 행위자처럼 사고하고 말하고 반응하는 인공지능 캐릭터입니다.
- 이 에이전트들을 통해 협상, 갈등, 의사결정, 여론 형성 등 복잡한 정치 과정을 실험적으로 재현할 수 있습니다.
- 중요한 점은, 단순히 텍스트를 생성하는 것이 아니라 ‘상호작용과 변화’가 가능한 정치적 생태계를 시뮬레이션한다는 것입니다.
⚖️ 생성 작업과의 차이점은?
| 목적 | 부족한 데이터를 생성하기 위함 | 정치적 행위자들의 상호작용을 모델링하기 위함 |
| 출력물 | 독립적인 텍스트 또는 데이터 | 전략, 협상, 감정 변화 등 상호작용 결과 |
| 방법론 | 프롬프트에 따른 결과 생성 | 에이전트 간 상호작용을 통한 동적 시나리오 전개 |
| 활용 예 | 가상의 여론조사 응답 생성 | 국제협상 시뮬레이션, 여론 극화 실험 등 |
🧠 행동 역학 시뮬레이션: 정치는 어떻게 움직이는가?
LLM을 활용한 **행동 역학 시뮬레이션(Behavior Dynamics Simulation)**은 정적인 데이터 분석이 아니라, 시간의 흐름과 상황의 변화에 따라 **정치 행위자(agent)**가 어떻게 행동을 바꾸는지를 가상 환경 속에서 실험할 수 있는 새로운 연구 방식입니다. 이는 인간처럼 학습하고, 반응하고, 전략을 조정하는 **‘정치적 인공지능 행위자’**를 만들어 그들의 상호작용을 관찰하는 방식입니다.
기존의 전통적 시뮬레이션 방식, 예컨대 **Agent-Based Models(ABM)**는 일정한 규칙을 정해 놓고 그 안에서 에이전트들이 움직이게 했습니다. 하지만 이 방식은 현실 정치의 복잡성과 예외적인 상황을 충분히 반영하지 못했습니다. 이에 비해, LLM 기반 시뮬레이션은 훨씬 유연하고 자연스러운 대화, 감정, 전략 변경까지 모사할 수 있습니다.
아래는 실제 연구 사례들입니다.
📘 Dai et al. (2024): 사회계약 시뮬레이션
- Hobbes의 사회계약 이론을 LLM 시뮬레이션 환경에 구현한 사례입니다.
- 자원이 부족한 가상의 세계에서, 다양한 정치 행위자들이 갈등(conflict)을 거쳐 **협력(cooperation)**으로 이행하는 과정을 탐구합니다.
- 예: "국가나 정부는 왜 필요한가?" 같은 질문에 대해, AI 에이전트들이 서로 대화하며 질서 형성의 필요성과 방법을 자발적으로 도출해 나갑니다.
- 이를 통해 정치 질서의 기원, 갈등의 통제 방식, 권위 정당화 과정 같은 고전 정치철학의 주제를 실험적으로 접근합니다.
📘 Hua et al. (2024): 역사적 국제 분쟁 시뮬레이션
- 제1차, 제2차 세계대전과 같은 역사적 국제 정치 상황을 LLM 에이전트들이 모사합니다.
- 각국의 정치 지도자 역할을 맡은 AI들이 외교적 전략과 군사적 결정을 내리는 방식으로 정치-군사 전환의 동학을 살펴봅니다.
- “어떤 조건에서 외교가 실패하고 전쟁으로 전환되는가?” 같은 질문을 가상 시나리오 안에서 풀 수 있게 됩니다.
- 특히 국가 간 상호작용에서 신뢰, 협상, 전쟁 억제, 동맹 형성과 같은 요소들이 어떻게 결합되는지를 분석합니다.
📘 Jin et al. (2024): 문명 간 가치 충돌 시뮬레이션
- 이 연구는 인간 정치의 범위를 넘어, 서로 다른 세계관과 가치관을 가진 문명 간의 협력과 충돌을 시뮬레이션합니다.
- 예를 들어, 한 문명은 집단주의와 환경 중심의 세계관을, 다른 문명은 개인주의와 경제 중심의 세계관을 가진 경우, 그들 간의 이념 충돌이 어떻게 전개되는지를 LLM 에이전트를 통해 실험합니다.
- 이와 같은 시뮬레이션은 지구적 또는 미래적 정치 시나리오에서, 이념적 차이가 상호작용을 어떻게 결정하는지를 보여줍니다.
📘 Chuang et al. (2024): 여론 극화와 합의의 동학
- 이 연구는 각기 다른 정치 성향을 가진 다수의 AI 에이전트를 가상의 소셜 네트워크에 배치해, **의견 변화(opinion shift)**와 극화(polarization) 과정을 시뮬레이션합니다.
- 예를 들어, 처음에는 중도적인 입장을 가진 에이전트도 극단적인 의견을 가진 주변 에이전트들과 반복적인 상호작용을 하면서 점차 극단화되는 현상이 관찰됩니다.
- 반대로, 신뢰가 높은 소수의 에이전트가 **합의 형성(consensus building)**에 기여하는 사례도 확인됩니다.
- 실제 SNS에서 벌어지는 정치 집단화, 분열, 공감대 형성 과정을 AI 환경에서 실험 가능하게 한 사례입니다.
📘 Guan et al. (2024): AI 외교 시뮬레이션
- 국가를 대표하는 AI 에이전트들이 국제 정치 환경 속에서 협상하고, 전략을 조정하며, 동맹을 형성하거나 깨뜨리는 과정을 시뮬레이션합니다.
- 예컨대, "기후 변화 협약을 체결할 것인가", "경제 제재에 응할 것인가" 같은 문제에 대해 국가별 에이전트들이 각기 다른 전략을 구사하면서 외교적 균형을 찾아가는 모습을 보여줍니다.
- 이러한 시뮬레이션은 실제 외교에서 벌어지는 복잡한 전략적 상호작용을 모의실험 형태로 구현할 수 있다는 점에서, 국제정치 연구와 정책 시나리오 분석에 응용 가치가 매우 높습니다.
🧾 요약
LLM을 활용한 행동 역학 시뮬레이션은 다음과 같은 특징을 갖습니다:
- ✅ 인간과 유사한 전략적, 감정적, 상황 반응 능력을 지닌 에이전트를 활용
- ✅ 반복 실험이 가능하며, 정치적 동학의 다양한 조건을 설정하고 테스트 가능
- ✅ 이론 기반(예: 사회계약론, 전쟁이론 등) 또는 실제 상황 기반(예: 선거, 협상 등) 분석에 활용 가능
- ✅ 정치 질서 형성, 여론 극화, 국제 협상 등 폭넓은 연구 주제에 적용 가능
이 방식은 기존의 통계적 방법이나 이산적 시뮬레이션에서 접근하기 어려웠던 정치적 행동 변화의 미시적 동학을 생생하게 재현할 수 있도록 해줍니다. 앞으로 정치학에서 LLM 기반 시뮬레이션은 가상의 실험실 역할을 하며 이론 검증과 정책 실험의 새로운 장을 열어갈 것입니다.
💬 2. 텍스트 기반 토론 시뮬레이션: 말로 이루어지는 정치 실험
정치는 단지 행동과 전략의 문제만이 아니라, 말과 설득, 교섭과 논쟁의 영역이기도 합니다. 바로 이러한 측면을 LLM으로 시뮬레이션할 수 있는 것이 **텍스트 기반 토론 시뮬레이션(text-based discussion simulation)**입니다. 이 방식은 AI 에이전트들이 실제 정치인처럼 말하고, 반응하고, 협상하는 대화 시나리오를 구성하면서 정치적 상호작용을 재현합니다.
기존 행동 중심 시뮬레이션이 전쟁, 갈등, 협력 구조 등을 다뤘다면, 텍스트 기반 토론은 의견 교환, 입장 조정, 정치적 설득의 과정을 중심으로 분석합니다. 이는 특히 의회 내 협상, 다당제 협의, 외교 교섭과 같은 실제 상황을 LLM 환경에서 실험할 수 있게 해줍니다.
🏛️ Baker et al. (2024): 미국 상원 정책토론 시뮬레이션
- 이 연구는 AI 에이전트가 미국 상원의원 역할을 맡아, 특정 법안에 대한 토론을 시뮬레이션합니다.
- 에이전트는 각자의 이념 성향(진보, 보수, 중도 등)에 따라 발언을 하고, 법안에 찬성하거나 반대 입장을 피력합니다.
- 토론 중에는 타협안 제시, 수정안 협상, 정당 간 공감대 형성 등의 실제 의회 상황이 반영됩니다.
- 이를 통해 양당 정치의 협상 메커니즘, 입법과정에서의 이념 갈등, 의사결정의 언어적 구조 등을 분석할 수 있습니다.
⚖️ Moghimifar et al. (2024): 다당제 협상 시뮬레이션
- 이 연구는 유럽형 다당제 환경을 모델로 하여, 여러 당을 대표하는 AI 에이전트들이 **연립정부(coalition)**를 구성하는 과정을 시뮬레이션합니다.
- 각 당은 특정한 정책 우선순위와 이념을 갖고 있으며, 연립정부 구성을 위해 서로 조건을 제시하거나 양보를 합니다.
- 예를 들어, 진보 정당은 복지 확대를 요구하고, 중도 정당은 재정 균형을 고수하는 등 서로 다른 정책 목표를 갖고 대화합니다.
- 협상이 실패하거나 타협이 이루어지는 과정을 통해 실제 정치에서 연정 형성의 난점과 가능성을 관찰할 수 있습니다.
🌐 Guan et al. (2024): AI 외교 협상 시뮬레이션
- 이 연구는 국제 정치의 외교 무대를 시뮬레이션합니다. 각국을 대표하는 LLM 에이전트들이 조약 협상, 안보 동맹, 무역 조건 등에 대해 협상합니다.
- 예컨대 기후 변화 조약을 둘러싸고 선진국과 개발도상국이 이해관계를 조율하거나 서로의 입장을 설득하려는 상황이 생성됩니다.
- 이러한 시뮬레이션은 실시간 전략 수정, 동맹 관계의 재편, 서로 다른 가치관의 충돌과 조정 등을 실험할 수 있는 플랫폼이 됩니다.
🪐 Jin et al. (2024): 문명 간 가치 충돌의 언어적 협상
- 이 연구는 상상의 범주까지 확장됩니다. 서로 다른 철학과 언어를 가진 문명 간 텍스트 대화 기반 상호작용을 시뮬레이션합니다.
- 각 문명은 정치 체계, 사회 규범, 윤리 기준이 전혀 다르며, LLM은 그에 따른 논리를 구축해 설득하거나 반응하게 만듭니다.
- 결과적으로 이 실험은 이질적인 세계관이 어떻게 의사소통을 시도하고, 갈등하거나 합의할 수 있는가에 대한 통찰을 제공합니다.
🧾 요약
텍스트 기반 토론 시뮬레이션은 정치학 연구에 있어 다음과 같은 독특한 장점을 제공합니다:
- ✅ 정치적 협상, 설득, 의사소통 전략을 언어적 수준에서 시뮬레이션 가능
- ✅ 다양한 이념, 정책, 정당 성향을 반영한 정교한 AI 토론 구조 생성
- ✅ 연립정부 협상, 외교 조약, 입법 과정 등 실제 정치 상황을 모사 가능
- ✅ 텍스트 자료로부터 언어적 전환, 극화, 중재 과정 등을 분석할 수 있음
- ✅ 비정형적인 또는 상상적 세계관에서도 담론의 가능성을 탐색 가능
이러한 방식은 기존 행동 중심 시뮬레이션으로는 도달하기 어려운 정치 언어의 전략성과 상호작용의 복잡성을 실험적 분석 도구로 전환해줍니다. 특히 정책 입안, 외교 협상, 여론조사 기반 담론 분석 등에서도 새로운 활용 가능성을 열고 있어, 향후 정치학과 NLP의 접점을 이끄는 중요한 시도라고 할 수 있습니다.
🔍 4.4. LLM의 설명가능성과 인과추론: 예측을 넘어 '이유'를 묻는 정치학
정치학에서 단순히 ‘무슨 일이 일어났는가’를 아는 것만으로는 부족합니다. 연구자는 늘 그다음 질문을 던져야 하죠. "왜 이런 일이 일어났는가?" 그리고 "다르게 했더라면 어떤 결과가 나왔을까?" 바로 이런 질문을 다루는 두 가지 핵심 개념이 **설명가능성(Explainability)**과 **인과추론(Causal Inference)**입니다. LLM은 이 두 영역에서도 점점 더 중요한 도구로 부상하고 있습니다.
🧠 설명가능성(Explainability)이란?
설명가능성이란, LLM이 내놓은 출력 결과가 어떤 이유로 그렇게 나왔는지를 사람이 이해할 수 있게 만드는 능력을 말합니다. 예를 들어, GPT가 “이 후보는 중도좌파적이다”라고 판단했다면, 왜 그렇게 판단했는지—어떤 단어나 맥락에 반응했는지—를 추적할 수 있어야 한다는 뜻입니다.
정치처럼 민감한 분야에서는 이런 투명성이 특히 중요합니다. 연구자는 물론이고 정책 결정자, 일반 유권자까지도 “이 모델이 왜 이런 결론을 내렸는가”를 납득할 수 있어야 하기 때문입니다. 그래야 LLM이 분석한 결과를 신뢰할 수 있고, 실제 정책 제안이나 정치 평가에 활용할 수 있습니다.
이때 사용되는 기법에는 다음과 같은 것들이 있습니다:
- 어텐션 메커니즘(attention mechanism): 모델이 어떤 단어나 문장에 가장 주목했는지 시각화해줍니다.
- 프롬프트 엔지니어링(prompt engineering): 입력 질문을 바꿔가며 모델의 반응을 유도하고 논리 구조를 파악합니다.
- 사후 분석(post-hoc analysis): 이미 나온 결과를 바탕으로 원인을 추적하는 해석 기법입니다.
이러한 방법들은 특히 텍스트 기반 데이터에서 **인과적 경로(causal pathway)**를 추정하거나, 특정 발언이나 정책 제안이 여론에 어떤 영향을 줄 것인지 분석할 때 유용합니다.
🔗 인과추론(Causal Inference)이란?
인과추론(causal inference)이란 어떤 현상이 왜 발생했는지를 과학적으로 설명하려는 시도입니다. 단순히 "A와 B가 관련이 있다"는 상관관계(correlation)를 넘어서, "A 때문에 B가 발생했다"고 말하려면 논리적, 통계적 근거가 필요합니다. 이것이 바로 인과추론의 핵심입니다.
정치학에서는 이 개념이 매우 중요합니다. 다음과 같은 질문들이 모두 인과추론의 영역에 해당합니다:
- 특정 정책이 실제로 유권자의 지지를 증가시켰는가?
- 선거 캠페인이 투표율에 영향을 미쳤는가?
- 민주주의가 경제 성장에 기여하는가?
이러한 질문에 답하려면 원인과 결과의 관계를 제대로 파악해야 하며, 이는 전통적으로 실험설계나 준실험(quasi-experiment), 회귀분석, 성향점수매칭(propensity score matching) 같은 통계적 방법으로 다뤄져 왔습니다.
그런데 문제는 여기에 있습니다. 많은 정치적 데이터는 정형화되어 있지 않고, 자연어 형태로 존재하며, 복잡한 담론 구조나 문화적 맥락을 내포하고 있습니다. 바로 이 지점에서 LLM이 기존 방법론을 보완해줄 수 있는 가능성이 생깁니다.
🧪 LLM이 인과추론을 돕는 방식
대규모 언어모델(LLM)은 단순히 말을 잘 만들어내는 AI가 아닙니다. 학습 과정에서 방대한 텍스트 데이터로부터 패턴, 순서, 인과 흐름을 파악하고, 이를 바탕으로 복잡한 정치적, 사회적 상황을 추론하는 능력을 어느 정도 갖추고 있습니다. 최근 연구들은 이런 모델이 인과추론의 일부 작업을 지원할 수 있음을 보여주고 있습니다.
아래는 LLM이 인과추론을 돕는 대표적 방식들입니다:
1. 🧬 인과 패턴 탐지
- LLM은 텍스트 속에서 원인과 결과를 암시하는 표현(예: "때문에", "결과적으로", "초래했다")을 학습합니다.
- 이를 바탕으로 인간이 놓칠 수 있는 **숨은 인과 관계(hidden causal dependencies)**를 추론할 수 있습니다.
- 예를 들어, 수천 개의 정치연설문을 분석하여 특정 수사전략이 여론 변동과 어떻게 연결되는지를 자동 추출합니다.
2. 🔄 반사실 시나리오 생성 (Counterfactual Generation)
- “만약 다르게 행동했다면 무슨 일이 벌어졌을까?”를 묻는 반사실 시나리오(what-if scenario)는 정책 평가에 매우 중요합니다.
- LLM은 텍스트 기반으로 이러한 시나리오를 생성할 수 있어, 정치학자들이 정책 대안 비교 분석을 할 수 있게 해줍니다.
- 예: “만약 2020년 대선에서 특정 주에서 투표 제도가 달랐다면 결과가 어떻게 바뀌었을까?”
3. 🧪 실험 시나리오 설계 및 데이터 생성
- LLM은 특정 조건에 따라 가상의 인터뷰나 뉴스 기사, 응답 문장 등을 생성할 수 있습니다.
- 이를 활용해, 전통적인 실험 디자인을 시뮬레이션하거나 성향 점수 매칭 등의 인과 추정법 검증에 활용되는 synthetic dataset을 생성할 수 있습니다.
- 예: GPT로 생성한 응답자 데이터로 여러 인과 추정법(예: IPW, DiD 등)을 비교 평가하는 연구도 있습니다.
4. ⚖️ 필요충분 조건 도출
- LLM은 다양한 정책 조건과 결과 사이의 연결을 학습하면서 “어떤 조건이 반드시 있어야 결과가 발생하는가?”, 또는 **“어떤 조합이 결과를 확실하게 낳는가?”**에 대한 추론도 할 수 있습니다.
- 특히 QCA(정성적 비교분석)적 접근과 결합될 수 있는 가능성이 제기되고 있습니다.
5. 🔁 Carryover 효과 없는 실험 수행
- 인간 실험에서는 이전 질문이 다음 질문에 영향을 주는 carryover effect가 발생하지만, LLM은 프롬프트를 초기화하면 항상 ‘제로 상태’에서 응답합니다.
- 이 점은 LLM이 실험용 인과추론에 매우 유용하다는 강점으로 작용합니다.
💡 장점과 한계
✅ 장점
- Carryover 효과 없음: 인간 실험자와 달리, LLM은 매번 완전히 새로운 상태에서 응답할 수 있기 때문에 전 실험의 영향 없이 순수한 비교가 가능합니다.
- 자연언어 기반 인과 그래프 생성: 모델은 배경지식과 텍스트 흐름을 바탕으로 인과적 연결 고리를 생성해낼 수 있습니다.
- 고비용 실험을 대체: 실제 대규모 실험 없이도 다양한 인과적 조건을 설정해 실험 가능
❗️한계
- “Causal Parrot” 문제: 모델이 진짜 인과관계를 이해한다기보다, 단순히 훈련된 데이터를 재현할 가능성이 큽니다. 즉, 패턴은 인식하지만 추론은 하지 못하는 문제가 있습니다.
- 출력의 불안정성: 질문을 조금만 다르게 해도 답이 바뀌거나 논리가 흐트러지는 경우가 있습니다.
- 윤리적 문제: LLM이 제시한 인과적 해석이 현실에 오용될 경우, 정책 판단 오류나 정치적 왜곡으로 이어질 수 있습니다.
🧾 요약
정치학에서 LLM은 단순한 텍스트 분석 도구를 넘어, 인과 관계 탐색과 설명 능력을 갖춘 이론적 파트너로 진화하고 있습니다. 그 가능성은 다음과 같습니다:
- 정책 효과의 인과 분석을 자동화
- 대안 시나리오(what-if) 기반 정책 실험
- 인과 모델 검증용 가상 데이터 생성
- 정치적 설명력 강화 (설득 가능한 분석 결과)
그러나 여전히 설명력의 신뢰성, 인과성의 해석 가능성, 정치적 활용의 윤리성 같은 측면에서 더 많은 연구와 검증이 필요합니다. 앞으로 정치학자와 AI 연구자의 협업을 통해 이 영역은 더욱 풍부하고 정교하게 발전할 수 있을 것입니다.
⚖️ 4.5 LLM 개발과 활용의 윤리적 쟁점
🔍 1. LLM에 내재된 가치와 편향에 대한 일반적 우려
LLM은 단지 기술이 아니라, 정치적·사회적 담론을 형성하고 강화하는 도구로 점점 더 큰 영향력을 갖고 있습니다. 그런데 이러한 모델은 "중립적인 기계"가 아닙니다. 실제로는 개발 과정에서 다음과 같은 중요한 선택들이 포함됩니다:
- 어떤 데이터로 학습시킬 것인가?
- 어떤 가치를 반영할 것인가?
- 누구의 시각이 대표되고, 누구의 목소리가 소외되는가?
이러한 점 때문에 LLM은 특정한 도덕적 프레임과 세계관을 ‘암묵적으로’ 반영하게 됩니다. 예를 들어, Johnson & Iziev (2023)은 AI가 생성하는 콘텐츠에 대한 신뢰 문제를 지적하며, 이런 시스템이 실제 사회적 규범을 잘 따르면서도 동시에 유해한 편향을 반복하지 않도록 만드는 것이 쉽지 않다고 말합니다.
또한 Kim & Lee (2023)는 정치 캠페인에서 챗봇이 활용될 경우, 중립을 가장하면서도 특정 이념을 조용히 강화할 위험이 있다고 지적합니다. Lee et al. (2023)의 연구에 따르면 LLM은 종종 사회적으로 열세에 있는 집단을 더 단순하게 묘사하는 경향을 보이며, 이는 인간 인지의 오래된 편향과 구조적 불평등을 반영하는 것일 수 있습니다.
⚠️ 2. 실제 모델 응답에서 나타나는 편향의 형태
이론적인 문제를 넘어서, LLM이 생성하는 텍스트 자체에서도 측정 가능한 편향이 발견됩니다. 예를 들면:
- Tornberg (2023)의 연구는 ChatGPT가 서구 중심 문화와 전문용어를 선호하는 경향이 있으며, 이는 비서구권 사용자에게 소외감을 줄 수 있다고 지적합니다.
- Stanczak et al. (2024)은 성별이나 직업에 대한 미묘한 고정관념이 여전히 존재함을 수량화하는 방법론을 제시했습니다.
- Jiang et al. (2024)은 지역사회 기반 데이터로 학습된 LLM이 특정 커뮤니티의 규범을 반영할 수는 있지만, 넓은 맥락에서 사용할 경우 이념적 분절과 에코체임버를 강화할 수 있음을 경고합니다.
이런 편향은 단지 "데이터의 문제"가 아니라, LLM이 사회적 현실을 재현하거나 강화하는 방식을 통해 현실에 영향을 미치는 구조적 문제로 발전할 수 있습니다.
🛠 3. 편향 완화를 위한 실질적 전략들
LLM의 편향을 줄이기 위한 다양한 실천 전략도 연구되고 있습니다.
- Rozado (2023)는 이념적 균형을 고려한 데이터 수집 전략을 제안하며, 다양한 정치 성향을 대표하도록 학습 데이터를 설계하면 모델의 정치적 편향을 줄일 수 있다고 주장합니다.
- Motoki et al. (2024)은 소외된 집단의 피드백을 반복적으로 모델 학습에 반영하는 방식을 강조합니다. 이 피드백 루프는 모델이 보다 다양한 문화를 반영하도록 돕습니다.
- Simmons (2024)는 명시적인 도덕적 추론 프레임워크를 모델 내부에 통합해야 한다고 주장합니다. 윤리적 가이드라인과 의사결정 원칙이 내장되어야, 모호한 상황에서도 일관성 있는 판단을 할 수 있게 된다는 것입니다.
이러한 접근법들은 단지 기술적으로 편향을 줄이는 것이 아니라, 모델을 보다 신뢰받을 수 있는 사회적 도구로 만들기 위한 윤리적 조치로 간주됩니다.
🌍 4. 사회 전체에 미치는 장기적 영향
LLM의 편향은 단순한 기술 문제가 아니라, 사회 구조를 재생산하고 왜곡할 수 있는 중요한 요소로 작용할 수 있습니다.
- Tornberg는 ChatGPT가 특정 문화적 집단에 대해 민감하지 않은 응답을 생성할 때, 이는 교육, 공공 담론, 정책결정 과정에서 제도적 불평등을 고착시킬 수 있다고 경고합니다.
- Alvarez et al. (2024)는 LLM이 잘못된 정보나 정치적 왜곡 콘텐츠를 강화하면, 공공 신뢰를 손상시키고 사회적 분열을 촉진할 수 있다고 말합니다.
- Hackenburg & Margetts (2024)는 정치 마이크로타게팅과 광고에서 LLM이 특정 집단을 조작하는 서사를 생성하면, 민주적 자기결정권을 위협할 수 있다고 지적합니다.
즉, LLM은 잘 쓰이면 민주주의를 강화할 수 있지만, 오용되면 사회적 불평등, 왜곡된 정보 확산, 권력 편향을 심화시킬 위험이 큽니다.
🧩 요약과 앞으로의 과제
LLM과 사회적 가치, 편향 문제는 복잡하지만 꼭 해결해야 할 영역입니다. 학계와 기술 커뮤니티가 함께 다음의 세 가지를 지향할 필요가 있습니다:
- 인지(Awareness): LLM이 어떻게 편향을 드러내는지 깊이 이해하고,
- 책임(Accountability): 다양한 사회 집단의 필요에 부합하도록 윤리적 기준을 갖추고,
- 투명성(Transparency): 실제 응답에서 편향을 식별하고 줄일 수 있는 메커니즘을 개발해야 합니다.
이러한 방향에서, LLM은 정치 분석이나 사회과학 연구뿐 아니라 정보 정의, 민주적 의사소통, 공공 신뢰 구축에 중요한 역할을 할 수 있습니다.
🌐4.6. LLM이 사회에 미치는 영향: 정치, 정보, 민주주의의 지형을 바꾸는 힘
대형 언어모델(LLM)의 발전은 단순한 기술 혁신이 아니라, 정치적 실천과 사회적 구조에 직접적인 영향을 미치는 ‘사회의 인프라’로의 진입을 뜻합니다. 정치과학자에게 중요한 질문은 바로 이것입니다: 이러한 기술이 어떻게 선거와 캠페인을 바꾸고, 유권자와 시민이 정보를 이해하고 참여하는 방식을 새롭게 정의하는가? 이 절에서는 LLM의 사회적 파급효과를 네 가지 측면에서 자세히 살펴봅니다.
🗳 1. 정치 캠페인의 혁신: 초개인화된 메시징과 전략 수립
LLM은 정치 캠페인의 전략적 역량을 비약적으로 확장시킵니다.
- Hackenburg (2024)는 대형 언어모델이 유권자 데이터에 기반해, 각 개인의 특성에 맞춘 메시지를 자동 생성할 수 있다는 점을 강조합니다. 이는 기존의 ‘일반 대중용 연설문’이 아니라, ‘당신만을 위한 메시지’가 될 수 있다는 것을 의미합니다.
- Moghimifar et al. (2024)은 LLM 기반 에이전트를 활용해 **정당 간 연립 협상(coalition negotiation)**을 시뮬레이션함으로써, 실제 선거 전략의 설계와 조정이 어떻게 이루어지는지까지 모델링할 수 있다고 보여줍니다.
- Foos (2023)는 LLM이 다양한 언어로 자동 대화형 커뮤니케이션을 가능케 하여, 복잡한 다언어 민주주의 사회에서의 선거 캠페인을 크게 효율화할 수 있음을 보여줍니다.
이러한 활용은 단순히 메시지를 빠르게 생성하는 데 그치지 않고, 선거의 전략·분석·대응 속도 자체를 바꾸는 체계적 변화를 예고합니다.
🗣 2. 정치 커뮤니케이션의 평등성과 접근성 향상
정치학 연구자들이 오랫동안 지적해온 문제 중 하나는 정책이나 정당 메시지가 너무 복잡해서 시민들이 제대로 이해하지 못한다는 점입니다. LLM은 이 장벽을 크게 낮춰줄 수 있습니다.
- Argyle et al. (2023)은 LLM이 **정당 강령(manifesto)**을 요약하고, 이해하기 쉬운 언어로 번역해주는 역할을 할 수 있다고 말합니다.
- Alvarez et al. (2024)은 선거 관련 정보를 명확하게 정리하고 제공함으로써, 유권자가 정보의 비대칭성을 줄이고 스스로 판단할 수 있도록 돕는 역할을 할 수 있다고 설명합니다.
이러한 기능은 특히 정보 접근이 어려운 저소득층, 비영어권, 정치 무관심층에게도 유의미한 변화를 불러올 수 있으며, 정보 민주화의 실질적 기반이 됩니다.
📚 3. 정보의 민주화: 누구나 이해할 수 있는 정치 정보
LLM은 복잡한 법안이나 정책 논의, 정당의 이념적 차이를 일반 시민이 이해할 수 있는 언어로 바꾸는 능력을 가지고 있습니다.
- 이를 통해 정치적 문맹률을 낮추고, 더 많은 시민이 민주주의 과정에 참여할 수 있는 길을 열어줍니다.
- 예를 들어, 한 시민이 “기후 변화 관련 법안이 나에게 어떤 영향을 줄까?”라는 질문을 던졌을 때, LLM은 신속하고 간결한 형태로 핵심 요점을 정리해줄 수 있습니다.
결과적으로 이는 정치 시스템의 투명성과 시민 주권 강화로 이어질 수 있는 잠재력을 가집니다.
🚨 4. 윤리적 위험과 민주주의 훼손 가능성
하지만 모든 기술은 그림자를 동반합니다. LLM의 사회적 영향에서도 편향과 오용, 정보 조작, 여론 조작의 가능성은 명백합니다.
- Bai et al. (2024)은 LLM이 **사실처럼 보이는 허위 정보(fake but plausible)**를 매우 그럴듯하게 생성할 수 있기 때문에, 정치적 선전이나 여론 조작에 악용될 수 있는 위험을 지적합니다.
- Alvarez et al.는 LLM이 이념적으로 편향된 콘텐츠를 강화하거나 허위 정보를 정당화하는 방식으로 사용될 경우, 이는 정치적 양극화와 사회 불신을 심화시킬 수 있다고 경고합니다.
- Hackenburg & Margetts (2024)는 마이크로타게팅 기술과 결합된 LLM이 특정 계층에게 맞춤형 정치적 메시지를 보내 여론을 조작하거나, 유권자의 선택을 제한할 수 있음을 실증적으로 분석합니다.
이러한 위험은 단지 기술적인 문제가 아니라, 민주적 제도에 대한 신뢰와 참여의 기반 자체를 약화시킬 수 있는 구조적 위협입니다.
🧭 요약과 향후 과제: 기술을 어떻게 관리할 것인가
LLM이 정치와 사회에 미치는 영향은 극단적으로 이중적입니다. 정보 평등과 민주적 참여를 촉진할 수 있지만, 동시에 조작과 불신의 수단으로도 사용될 수 있습니다. 이 양면성을 제대로 관리하기 위해서는 다음과 같은 노력이 필요합니다:
- 책임 있는 도입 (Responsible Deployment): 정치적 맥락에서 LLM을 어떻게 사용할지에 대한 가이드라인 필요.
- 투명성 강화 (Transparency): LLM이 어떤 데이터를 기반으로 어떤 응답을 생성했는지를 추적할 수 있도록 설계.
- 대중 교육 (Public Awareness): LLM의 가능성과 한계, 위험성에 대한 사회 전반의 이해 제고.
- 허위정보 방지 (Misinformation Prevention): 알고리즘이 생성하는 콘텐츠를 검증하고 왜곡 가능성을 조기에 탐지하는 시스템 마련.
🗃 5. 1. 정치학에서 LLM이 잘 작동하려면, 제대로 된 ‘벤치마크 데이터’가 필요하다
정치과학 연구에서 LLM을 잘 활용하려면, 단순히 모델만 좋아서는 부족합니다. 정치적인 문맥을 충분히 반영한 데이터셋, 즉 “정치에 특화된 벤치마크 데이터셋”이 필요합니다. 이 절에서는 감정 분석부터 선거 예측, 법안 요약, 허위정보 탐지, 분쟁 협상에 이르기까지 다양한 응용 분야에 사용되는 대표적인 데이터셋들을 구체적으로 소개합니다.
💬 감정 분석과 여론 데이터셋: 민심을 읽는 눈
정치과학에서 감정 분석(sentiment analysis)은 단순한 기계적 문장 분류 이상의 의미를 가집니다. 정치적 발언이 다층적인 감정과 이데올로기적 맥락을 담고 있는 만큼, LLM이 여론을 제대로 ‘읽기’ 위해서는 정교하게 설계된 감정 분석 데이터셋이 필요합니다.
🎯 주요 데이터셋 설명
- OpinionQA
- 내용: 1,489개의 질문을 기반으로 LLM이 공공 여론을 얼마나 정확하게 재현할 수 있는지를 테스트.
- 특징: 단순히 트윗 문장을 긍·부정으로 분류하는 것이 아니라, “미국인은 총기 규제에 찬성할까?” 같은 실질적이고 미묘한 질문에 대한 모델의 직관과 해석 능력을 평가합니다.
- 정치적 활용도: 설문조사 없이도 대중의 감정적 흐름을 모델로부터 유추할 수 있어, 비용 효율적인 여론 추정 도구로 유망합니다.
- PerSenT (Personalized Sentiment Tracking)
- 내용: 뉴스 기사 안에 등장하는 특정 인물(예: 조 바이든, 푸틴 등)에 대한 감정이 어떤 방향으로 서술되는지를 추적.
- 특징: 하나의 인물에 대해 반복적으로 나타나는 언급들 속에서 감정을 집계하여 시간대별 감정 흐름을 보여줍니다.
- 정치적 활용도: 선거 후보에 대한 뉴스의 정서적 프레이밍, 정책에 대한 국민 감정 추이 등 정치 커뮤니케이션 분석에 유용합니다.
- GermEval-2017
- 내용: 독일 철도청 서비스에 대한 불만/칭찬 코멘트를 모은 데이터.
- 특징: “시간 엄수”나 “소음” 같은 세부 속성(aspect) 기반으로 감정 분석이 이루어지므로, 단순한 이분법이 아닌 복합적 평가 모델링이 가능합니다.
- 정치적 활용도: 행정 서비스에 대한 시민의 피드백 분석에 적합하며, 정책 만족도 평가 등으로 확장할 수 있습니다.
- 다국어/다문화 여론 데이터셋
- Twitter, Bengali News, Indonesia News 등 다양한 언어 기반 뉴스와 댓글 데이터로 구성.
- 특징: 언어적·문화적 차이를 반영한 감정 모델 평가 가능. 특히 영어 중심 모델의 편향성 평가에 중요합니다.
- 정치적 활용도: 비서구권 여론 분석, 세계적 선거 감정 흐름 비교 연구 등에 사용됩니다.
📌 왜 중요한가?
이러한 데이터셋들은 단순히 "좋다/싫다"를 넘어서, 여론의 뉘앙스, 맥락, 대상에 따른 감정 흐름을 정밀하게 추적하는 데 필수적입니다. 특히 LLM이 정치 관련 문서를 요약하거나 답변을 생성할 때, 배경에 깔린 감정 구조를 이해하는 것은 정확하고 균형잡힌 결과를 생성하는 데 결정적 역할을 합니다.
🗳 선거 예측과 투표 행태: 장기적 트렌드를 학습하는 데이터셋
선거는 정치학에서 가장 많이 연구되는 주제 중 하나입니다. LLM이 신뢰할 수 있는 예측 도구가 되려면, 단순히 최근 몇 년간의 데이터만 보는 것이 아니라, 수십 년간 누적된 대규모 선거 데이터를 학습해야 합니다.
📚 주요 데이터셋 설명
- U.S. Senate Statewide Returns (1976–2020)
- 내용: 미국 상원 선거 데이터를 주 단위로 정리한 데이터셋.
- 특징: 거의 45년에 달하는 연속적 데이터를 포함하여, 정당 변화, 유권자 성향 이동, 지역별 패턴을 LLM이 학습할 수 있도록 구성.
- 정치적 활용도: 중장기 선거 전략 설계, 정당 재편 분석 등.
- U.S. House Returns (1976–2022)
- 내용: 미국 하원 선거 결과를 선거구 단위로 수록.
- 특징: 더 미시적인 수준의 데이터를 통해, 지역적 이슈, 게리맨더링 효과, 후보 개인 효과 등을 LLM이 파악할 수 있도록 지원.
- 정치적 활용도: 선거 캠페인 최적화, 유권자 마이크로 타게팅 연구 등에 유용.
- Precinct-Level Returns 2018
- 내용: 개별 투표소(precinct) 수준의 미국 선거 결과, 총 1천만 개 이상의 데이터 포인트 포함.
- 특징: 미국 정치 데이터 중 가장 세밀한 수준으로, 도심 vs 교외, 인종/소득 집단 간 투표 격차 분석 등에 필수.
- 정치적 활용도: LLM이 지역 불균형, 인구 사회학적 투표 경향까지 반영한 분석 수행 가능.
- ANES 2008 & 2016 Time Series Studies
- 내용: 선거 전후에 걸쳐 설문을 통해 유권자의 태도, 감정, 정책 입장을 기록한 시계열 데이터.
- 특징: 같은 사람에게 선거 전·후 질문을 던진 설계를 통해, 감정 이동과 정책 수용성 변화를 정밀하게 추적할 수 있음.
- 정치적 활용도: LLM이 정책 효과나 선거 캠페인의 여론 변화 유도력을 추정하는 데 사용.
- U.S. President 1976–2020
- 내용: 미국 대선 데이터를 통합적으로 정리한 데이터셋.
- 특징: 정당 대결 구도, 삼자 구도 효과, 주별 스윙 등 전국적 선거 전략 분석의 기본 자료.
- 정치적 활용도: 대선 여론 추이 예측, LLM 기반 시나리오 분석 등에 유용.
🔍 왜 중요한가?
정치적 의사결정과 정책 수립에 있어, 과거의 데이터에서 정교한 패턴을 인식하고 미래를 예측하는 능력은 핵심입니다. LLM이 선거 예측에 강력하게 쓰이기 위해서는 단순 텍스트 정보가 아니라, 정치적 행동에 관한 구조화된 숫자 데이터를 이해하고 활용할 수 있어야 합니다.
📜 법안 및 행정규칙 분석: 입법정보 요약과 이해
정치학 연구나 정책 분석에서 입법 문서와 행정 규칙은 가장 핵심적인 1차 자료입니다. 그러나 이 문서들은 보통 수십 쪽에 달하고, 전문용어와 법률적 문장이 뒤섞여 있어 연구자와 일반 시민 모두에게 이해의 장벽이 높습니다. LLM은 이러한 법적·행정적 문서를 신속하고 정확하게 요약해주며, 정책 결정과 법안 분석을 자동화하는 데 강력한 도구가 됩니다.
🗂️ 주요 데이터셋과 응용
- BillSum
- 내용: 미국 의회의 33,422개 법안 텍스트와 그에 대응되는 요약 정보로 구성.
- 기능: LLM이 이 데이터를 학습하면, 실제 법안 내용 요약을 매우 자연스럽게 생성할 수 있음.
- 연구 활용도: 연구자는 수천 건의 법안을 하나하나 읽지 않고도, 자동 요약 결과를 통해 정책 동향이나 입법 패턴을 빠르게 파악할 수 있음.
- CaseLaw
- 내용: 693만 건 이상의 주(state) 및 연방(federal) 법원 판례 데이터로 구성.
- 기능: 사법적 판결의 논리를 LLM이 학습할 수 있게 하여, 판례 기반의 예측 및 비교 분석이 가능해짐.
- 정치과학 활용도: 정치적 사안에 대한 법원의 판단 경향, 법적 담론의 변화, 규범적 정당성 분석 등에 사용됨.
- Federal Register Dataset
- 내용: 2000년부터 2014년까지의 연방정부 행정규칙(final rule)에 대한 제목과 요약.
- 기능: LLM이 이를 바탕으로 규제 정책의 트렌드 및 변화 흐름을 자동 감지하고 요약 가능.
- 정책학 활용도: 특정 이슈(예: 환경, 노동, 무역)에 대한 행정부의 규제 방향성과 빈도 분석 가능.
- DEU III Dataset (EU 의사결정 데이터)
- 내용: 유럽연합(EU)에서 제안된 141개 법안과 363개의 쟁점 데이터.
- 기능: LLM이 각 회원국의 입장 차이, 협상 전략, 정책 조율 과정을 학습할 수 있음.
- 정치외교 연구 활용도: EU 통합 연구, 다국간 정책 형성과정, 협상 전략 분석 등.
💡 정치학에서 왜 중요한가?
입법과 행정 규칙은 국가 권력의 핵심 수단입니다. 그런데 이 텍스트들은 너무 길고 복잡하기 때문에, 대중은 물론이고 전문가조차 실시간으로 모든 법안을 검토하기 어렵습니다. LLM은 이 문제를 해결하며, 입법 감시, 정책 비교, 정당 분석, 시민 교육에 있어 정보 격차를 줄이는 역할을 수행합니다.
📰 허위정보 탐지: 가짜 뉴스와 과장된 주장 구별하기
현대 정치에서 허위정보와 과장된 주장은 민주주의 자체에 위협이 될 수 있습니다. 선거, 팬데믹, 전쟁과 같은 주요 사안에서 퍼지는 잘못된 정보는 유권자의 판단을 흐리고 사회적 분열을 촉진합니다. 이러한 허위정보 탐지를 위해 LLM은 기존의 룰 기반 필터나 단순한 fact-check보다 훨씬 정교한 접근이 가능합니다.
🔍 주요 데이터셋과 응용
- PolitiFact Dataset
- 내용: 유명 팩트체크 사이트 PolitiFact의 아카이브와 사용자 반응 데이터 기반.
- 기능: LLM이 특정 발언이나 기사에 대한 진실성 판단을 학습함. 예: “바이든이 모든 주에 군대를 보냈다” → False.
- 정치학 활용도: 정치적 커뮤니케이션의 사실성 평가, 정치인 발언의 팩트 체크 자동화.
- GossipCop Dataset
- 내용: 연예계 및 대중 문화 관련 루머를 다루지만, 텍스트의 설득력과 구조적 허위성 감지라는 점에서 훈련에 매우 유용.
- 기능: 감성적 언어, 과장된 표현, clickbait 요소를 LLM이 구별할 수 있도록 학습 가능.
- 사회학적 활용도: 대중적 루머의 구조를 이해하고, 허위정보의 확산 패턴을 분석하는 데 활용.
- Weibo Fake News Dataset
- 내용: 중국 SNS 위챗 기반의 가짜 뉴스(4,488건)와 진짜 뉴스(4,640건) 분류 데이터.
- 기능: 비영어권 허위정보 탐지에도 LLM이 대응할 수 있도록 다국어 훈련 지원.
- 글로벌 정치 연구 활용도: 비민주국가에서의 정보 통제, 시민 담론 왜곡 현상 등 비교정치 분야에 응용 가능.
- SciNews Dataset
- 내용: 과학·의료 관련 뉴스에 특화된 허위/진실 기사 2,400건.
- 기능: LLM이 과학적 주장과 음모론을 구별하는 데 특화됨.
- 보건 정책/기후 변화 연구 활용도: 공공정책 이슈에서 허위정보가 여론에 어떤 영향을 주는지 분석할 수 있음.
⚠️ 왜 중요한가?
LLM은 단순한 키워드 필터가 아니라, 문장의 논리 구조, 맥락, 주장 방식까지 분석할 수 있는 능력을 갖고 있습니다. 따라서 팩트 체크를 넘어, 허위정보가 왜 설득력을 갖는지, 어떤 집단이 이를 신뢰하는지까지 분석할 수 있습니다. 이는 선거 개입, 혐오 표현, 정치적 음모론의 추적에 있어 사회적 책임 있는 AI 사용의 핵심 영역입니다.
🕊 협상 시뮬레이션과 게임이론: 분쟁과 평화의 언어
LLM이 ‘갈등 해결’을 분석하려면, 협상의 말뭉치가 필요합니다.
- UCDP, PNCC는 실제 내전과 평화협정의 사례들을 포함하고 있어, LLM이 누가 어떻게 협상하고 어떤 조건에서 평화에 도달했는지를 분석할 수 있게 도와줍니다.
- WebDiplomacy는 사용자가 서로 외교적으로 협상하며 승리를 추구하는 온라인 게임의 대화 데이터를 기반으로, LLM이 전략적 언어와 의도 파악 능력을 학습하게 합니다.
이 데이터들은 국제 정치, 무력 충돌, 전략적 협상 분석을 연구하는 데 특히 유용합니다.
✅ 정리: LLM의 정치학 적용, 데이터가 전부다
이 절에서 정리된 다양한 데이터셋들은 단순히 기술적 성능 측정을 위한 게 아닙니다. 정치학이라는 맥락에서 LLM이 현실 문제에 얼마나 정밀하게 적응할 수 있는지를 시험하고 훈련하는 실험실입니다. 감정, 투표, 법안, 가짜 뉴스, 협상 시뮬레이션 등 정치과학의 거의 모든 주요 영역을 포괄하는 데이터들이 갖추어져 있기에, LLM은 단순한 언어 도구를 넘어서 실제 정치 분석 도구로서 활용될 수 있습니다.
📊 5.2. LLM을 위한 정치 데이터셋 구축 전략: 어떻게 시작할 것인가?
LLM(대형언어모델)을 정치학에 응용하려면, 단순히 모델을 호출하는 것만으로는 부족합니다. 핵심은 모델이 학습할 수 있는 고품질 정치 데이터셋을 어떻게 준비하느냐입니다. 특히 정치 분야는 민감하고 맥락 의존적이며, 사회문화적으로 편향이 개입되기 쉬운 영역이기 때문에, 그만큼 데이터 준비 과정이 정교해야 합니다.
🗂️ 데이터 수집: 공공 정치 텍스트에서 시작하기
LLM을 정치학 연구에 효과적으로 적용하려면, 무엇보다 먼저 정치적으로 유의미한 텍스트 데이터를 수집하는 작업이 필수입니다. 여기서 핵심은 단순히 ‘정치 관련 텍스트’를 모으는 것이 아니라, 모델이 학습을 통해 정치적 맥락과 입장을 해석할 수 있도록 돕는 정제된 데이터를 구축하는 것입니다.
그렇다면 어떤 데이터를, 어디에서, 어떻게 수집해야 할까요?
🔎 대표적인 수집 대상
- 정치 연설문: 대통령 연설, 국회의원 연설, 청문회 발언 등
- 국회 기록 및 입법자료: 법안 원문, 표결 결과, 국회 회의록
- 정치 뉴스 기사: 특정 사건, 정책, 선거 관련 기사
- 정당 플랫폼 및 정책 공약집: 각 정당의 이념과 정책 방향을 확인 가능
- 여론조사 결과: 정량적인 민심 데이터, 특히 패널형 장기 조사
- SNS/커뮤니티 게시물: 일반 유권자의 의견, 특히 선거 전후의 변화 감지
이러한 자료는 대부분 공공기관 웹사이트, 뉴스 API, 오픈 데이터 포털, 학술 데이터 저장소 등에서 접근할 수 있으며, 비교적 라이선스 부담이 적은 경우가 많습니다.
🧠 정치적 텍스트 수집 시 주의할 점
- 정치적 다양성 확보: 한 정당이나 이념에 편중되지 않도록 다양한 스펙트럼을 반영
- 시의성 고려: 특정 시점에 집중된 자료는 모델의 일반화 능력을 저하시킬 수 있음
- 문체와 포맷의 통일성 확보: 모델 학습 시 노이즈가 되는 부분 제거 필요 (ex: 불필요한 HTML 태그, 중복 문장 등)
이러한 기준을 염두에 두고 데이터를 모아야 LLM이 정치적 문맥을 더 깊이 이해할 수 있습니다.
🧩 OpinionQA 데이터셋 구축 사례: 단계별 전략
LLM이 정치적 여론과 감정의 뉘앙스를 정교하게 이해하게 만들기 위해 특별히 설계된 대표적인 데이터셋이 바로 OpinionQA입니다. 이 데이터셋은 실제 여론조사 자료를 바탕으로 만들어졌으며, 정치, 사회, 과학 이슈에 대한 공공의 의견을 다양한 인구통계학적 조건 하에서 반영하는 것이 핵심입니다.
OpinionQA가 어떻게 만들어졌는지를 아래와 같은 단계별로 살펴볼 수 있습니다:
① 공공 데이터 출처 확보 (Data Source Selection)
OpinionQA의 기본 재료는 **Pew Research의 American Trends Panel (ATP)**과 같은 대규모 공공 여론조사 데이터입니다. 이 자료는 주제별로 잘 정리되어 있으며, 응답자의 연령, 소득, 교육 수준, 정치적 성향 같은 변수도 함께 제공됩니다.
② 데이터 선택 및 필터링 (Filtering for Relevance)
모든 질문이 OpinionQA에 적합한 것은 아닙니다. 따라서 연구자는 다음 기준에 따라 문항을 선별합니다:
- 정치 및 사회 쟁점에 대한 다양한 관점이 존재하는 질문
- 양극화가 뚜렷한 주제: 예) 기후 변화, 총기 규제, 의료 제도
- 다층적인 응답 가능성이 있는 항목: 단순한 찬반이 아니라 ‘매우 동의’, ‘다소 반대’ 등의 세부 척도가 있는 경우
이렇게 선별된 문항이 바로 LLM이 학습할 “질문-응답 쌍”의 재료가 됩니다.
③ 전처리 및 포맷 변환 (Preprocessing & Formatting)
OpinionQA는 LLM이 잘 이해할 수 있는 형식, 즉 객관식 문항 포맷으로 데이터를 변환합니다.
- 복잡한 응답들을 정규화해 4~5지선다 형태로 구성
- 중복 표현이나 모호한 응답은 정제하거나 제외
- 입력과 출력 포맷을 질문: ~, 선택지: A) ~ B) ~ ... 와 같은 통일된 구조로 정리
이렇게 포맷을 맞추는 과정이 있어야 모델이 다양한 질문 구조에도 잘 반응할 수 있습니다.
④ 응답자 속성 기반 라벨링 (Annotation by Demographics)
OpinionQA의 핵심은 단순 응답이 아니라 응답자 특성에 따른 여론의 분포를 모델이 학습하도록 만드는 것입니다. 그래서 각 질문에는 다음과 같은 정보들이 함께 라벨링됩니다:
- 연령대 (20대, 30대, 60대 이상 등)
- 정치 성향 (보수, 진보, 중도)
- 소득 수준
- 인종 및 지역 구분
이러한 라벨은 다층적 여론구조를 반영하는 학습을 가능하게 해주며, 나아가 LLM이 정치적 소수 의견도 포착하게 만드는 데 중요합니다.
⑤ 최종 OpinionQA 데이터셋 완성
이 과정을 거쳐 탄생한 OpinionQA는 총 1,489개의 질문 항목과 수만 건의 라벨된 응답 데이터를 포함한, 매우 구조화되고 정치적으로 정제된 QA 데이터셋입니다. LLM은 이를 바탕으로 다음과 같은 능력을 얻게 됩니다:
- 특정 이슈에 대한 다수 의견 예측
- 인구통계적 집단별 감정/여론 시뮬레이션
- 정치 캠페인 타겟팅을 위한 유권자 인사이트 분석
🖍 어노테이션 전략: 수작업 vs 자동화의 균형
정치 데이터를 LLM이 학습할 수 있는 형태로 바꾸기 위해서는 **‘어노테이션(주석)’**이라는 핵심 절차가 필요합니다. 여기서 어노테이션이란, 텍스트에 정치적 의미나 감정, 편향, 주체 정보 등을 태깅하는 작업입니다. 이 작업은 단순한 분류 이상의 의미를 가집니다. 왜냐하면 정치 담론은 뉘앙스와 맥락에 따라 크게 달라지기 때문입니다.
🔧 세 가지 어노테이션 방식
- 전통적 수작업 어노테이션 (Hand Labeling)
- 정치 전문가나 훈련된 코더가 하나하나 라벨을 붙이는 방식입니다.
- 예: 특정 기사에 대해 “보수적 시각”, “중도 입장”, “진보적 프레이밍” 등으로 주석 처리.
- 장점: 정확성 높음, 미묘한 의미 포착 가능.
- 단점: 시간 소모 크고 비용도 많이 듬.
- 반자동 어노테이션 (Semi-Automated Labeling)
- 알고리즘 또는 규칙 기반 필터가 1차 라벨링을 수행하고, 이후 전문가가 검수 및 수정.
- 예: 키워드 기반으로 자동 감정 분류 후, 사람의 점검을 거침.
- 장점: 효율성과 정확성의 균형, 대규모 작업에 적합.
- LLM 기반 자동 어노테이션 (Fully Automated using LLMs)
- LLM에게 프롬프트를 주고 정치 편향, 감정, 주체 등을 직접 분류하게 함.
- 이후 품질 검수만 수행.
- 장점: 확장성과 반복성 매우 높음.
- 단점: 정확성 검증이 필수. 편향된 결과를 그대로 학습시킬 위험 있음.
⚙️ 전략의 핵심
- 데이터의 민감도와 정치성향 다양성을 고려해 자동화 비율을 조절해야 합니다.
- ‘완전 자동화’는 비용은 낮지만 정치적으로 위험할 수 있습니다. 정치적 담론처럼 예민한 주제에서는 최소한의 전문가 개입이 필수입니다.
- 특히 감정 분석, 정책 프레임, 미디어 편향 탐지와 같은 정성적 해석이 필요한 분야에서는 수작업 또는 반자동 방식을 권장합니다.
⚖️ 데이터 편향과 대표성 문제: 반드시 점검할 것
정치 데이터를 다룰 때 가장 흔히 발생하는 문제 중 하나가 바로 **데이터 편향(bias)과 대표성 불균형(representation imbalance)**입니다. 이 두 문제는 LLM의 학습 결과를 왜곡시키고, 특정 정치적 입장을 과대표현하거나 소수 의견을 배제하게 만들 수 있습니다.
🔍 예시로 보는 편향의 사례
- 보수 성향 뉴스만 수집한 경우 → 진보적 주장에 대한 학습 부족
- 특정 연령대 여론조사만 활용한 경우 → 젊은층 혹은 고령층 의견의 누락
- 영어권 데이터만 기반으로 한 경우 → 다문화 정치 담론에 대한 이해 부족
📏 해결 전략
- 이념적 균형 유지
- 좌-우 진영의 뉴스, 성명서, 정책문서를 의도적으로 균형 있게 포함
- 예: 공화당과 민주당 성명서를 동수 확보
- 민족/지역/성별/연령 다양성 확보
- SNS나 설문 데이터를 활용할 때 다양한 인구집단을 포함하도록 설계
- 부족한 집단은 oversampling하거나 LLM 기반 synthetic data로 보완
- 정치체제 다양화
- 미국 중심 데이터 외에 **다양한 정치제도(의회제/대통령제 등)**를 포함
- 예: 유럽의 연립정부 사례, 아시아 국가의 권위주의 선거 사례 포함
이러한 과정 없이는, 아무리 좋은 모델이라도 ‘편향된 학습’을 통해 실제 연구에 신뢰할 수 없는 결과를 내놓을 수 있습니다. 특히 정치적으로 민감한 분석에선 반드시 이 문제를 선제적으로 점검해야 합니다.
🧼 전처리와 정규화: 정치적 언어의 복잡성을 다듬기
정치 텍스트는 일상언어보다 훨씬 복잡하고, 추상적인 표현도 많습니다. 이를 LLM이 잘 이해하고 학습하도록 만들기 위해서는 **전처리(preprocessing)**와 정규화(normalization) 단계가 중요합니다. 이는 데이터를 “학습하기 좋은 상태”로 다듬는 작업입니다.
🧹 전처리 주요 단계
- 불필요한 기호 제거
- HTML 태그, 각주, 이모티콘, 기계번역 흔적 등 제거
- 불균형 표현 정제
- 예: ‘극좌파’, ‘빨갱이’ 같은 자극적 용어 → 중립적 언어로 정리
- 정치적 개체명 인식 (NER)
- ‘윤석열’, ‘민주당’, ‘우파 정당’ 등을 **엔티티(entity)**로 정리
- 모델이 주체(행위자)를 명확히 인식하게 만듦
- 구문 정렬
- 국회 발언록이나 SNS 텍스트처럼 비정형 문장을 문법적 순서로 정리
🔄 정규화 전략
- 표준 어휘 통일: 동일 개념의 다양한 표현(예: ‘기후위기’ vs ‘환경재앙’)을 통일
- 의미 단위로 문장 분할: 복합문장을 짧은 단위로 나눠 학습 안정성 확보
- 특정 프레임 제거 또는 보존: 정치적 프레임이 분석 대상인지 아닌지에 따라 해당 요소를 제거하거나 강조
🔁 데이터 확장 전략: 부족한 데이터를 LLM으로 채우기
정치 데이터는 민감하고 공개 범위가 제한되어 있는 경우가 많기 때문에, 충분한 데이터를 얻기 어렵습니다. 이때 사용되는 방법이 **데이터 증강(data augmentation)**입니다.
- LLM으로 새로운 여론조사 시뮬레이션 생성
- 기존 문장의 패러프레이징(paraphrasing)
- 이념적으로 다양한 주장 자동 생성
예를 들어, 과거 선거 데이터를 기반으로 다양한 지역·이념별 유권자 시나리오를 생성해 모델을 훈련시킬 수 있습니다.
💡 실제 사례 세 가지
- 정치적 편향 제거를 위한 데이터셋 구축
- 좌우 성향이 골고루 담긴 연설문, SNS, 기사 모음
- 각 텍스트에 이념 성향과 프레이밍 라벨 부여
- LLM으로 법안 해석 어노테이션 자동화
- BillSum 데이터셋을 기반으로 LLM이 자동으로 법안 주요 내용에 태그 달기
- 정책 카테고리, 이해관계자, 예산 항목 등 자동 분류
- 선거 예측용 합성 데이터 생성
- 과거 여론조사를 기반으로 LLM이 다양한 투표 패턴 시뮬레이션 생성
- “20대 보수층의 투표율이 높아지면 결과가 어떻게 바뀔까?” 등 가상 시나리오 설계 가능
🔧5.3. LLM을 정치학 응용에 맞추기: 입법 요약 과제를 중심으로 한 파인튜닝 전략
정치학 연구에 LLM을 실질적으로 적용하기 위해서는, 단순한 프롬프트 엔지니어링을 넘어 **도메인 특화 파인튜닝(domain-specific fine-tuning)**이 필요합니다. 특히 입법문서와 같은 복잡하고 계층적인 텍스트를 요약하는 작업은, 기존의 일반 텍스트 요약 방식으로는 한계가 있습니다. 본 절에서는 미국 의회 법안 요약 데이터셋인 BillSum을 활용해 LLM을 정치적 문서 요약에 최적화하는 구체적인 파인튜닝 과정을 다룹니다.
📚 1. 도메인 특화 데이터셋: BillSum
정치학 연구에서 LLM을 효과적으로 활용하기 위해서는, 일반적인 뉴스나 웹 텍스트가 아니라 정치 도메인에 특화된 데이터셋이 필수적입니다. 그 대표적인 예시가 바로 BillSum입니다.
BillSum은 미국 연방 의회(US Congress) 및 캘리포니아 주의 입법 문서들을 수집한 데이터셋으로, 약 22,000건 이상의 법안 원문과 전문가가 작성한 요약문으로 구성되어 있습니다. 이 데이터셋은 다음과 같은 점에서 도메인 특화적 성격을 강하게 지닙니다.
- 법률 문서 특유의 계층적 구조와 복잡한 문장 구성은 기존의 일반 텍스트 요약과는 질적으로 다릅니다. 단순한 핵심문 추출이 아니라, 정치적·법률적 함의까지 고려한 구조화된 요약이 필요합니다.
- 정책 영역별 분류(예: 환경, 세금, 교육 등)를 포함하고 있어, 정치학 연구자가 정책 비교나 입법 경향 분석에 활용하기에 적합합니다.
- Out-of-domain 테스트셋으로 구성된 캘리포니아 주 법안 데이터는, 모델의 일반화 능력까지 평가할 수 있게 해줍니다.
BillSum은 단지 LLM 학습용 데이터셋일 뿐만 아니라, 법안 요약 자동화라는 실용적 목표를 위해 설계된 전문성 있고 신뢰도 높은 자원입니다.
⚙️ 2. 파인튜닝 프로세스: 전체 절차 살펴보기
BillSum과 같은 데이터셋을 기반으로 LLM을 파인튜닝하는 과정은 일반적인 사전학습(pretraining)과 달리, 매우 정교하고 체계적인 절차를 필요로 합니다. 아래는 입법 요약을 위한 파인튜닝 전반을 단계별로 설명한 것입니다.
① 데이터 전처리 (Preprocessing)
- 각 법안 텍스트를 해당 요약문과 정렬하여 정확한 입력-출력 쌍을 구성합니다.
- 문단 구조를 유지하되, 지나치게 반복적인 법률 용어나 표제어는 제거하거나 정규화합니다.
- 특정 키워드(예: “enacts”, “shall be amended”)나 구조적 단서를 활용해 문서 내부 구조를 명확하게 파악할 수 있게 합니다.
② 경량 파인튜닝 셋업 (Efficient Fine-Tuning)
- 전체 모델 파라미터를 수정하지 않고도 도메인 특화를 가능케 하는 LoRA(Low-Rank Adaptation) 또는 Prefix-Tuning 기법을 적용합니다.
- 학습 효율성을 높이기 위해 GPU 기반의 분산 학습을 사용하며, 학습률, 배치 크기, 에폭 수를 정밀하게 조정합니다.
- 성능 평가는 ROUGE, BLEU, METEOR 등의 요약 품질 지표를 사용하여 정량적으로 수행합니다.
③ 훈련 및 검증 과정 (Training and Validation)
- 학습은 gradient accumulation과 mixed precision training 기법을 통해 메모리 사용을 최적화하면서 진행됩니다.
- 일정 간격마다 validation set에 대해 성능을 측정하며, 과적합을 방지하기 위한 early stopping 기준도 함께 설정합니다.
- 각 epoch마다 손실(loss)이 줄어드는지를 체크하며, 생성된 요약이 정답 요약의 핵심을 얼마나 충실히 반영하는지 비교합니다.
이러한 전처리–셋업–훈련의 구조적 흐름을 통해, LLM은 단지 언어 능력만 학습하는 것이 아니라, 정치적 텍스트의 구조와 함의까지 정교하게 반영할 수 있는 수준으로 발전하게 됩니다.
🧾 3. 프롬프트 엔지니어링: 요약 품질 향상의 핵심
LLM을 파인튜닝할 때, 단순히 데이터만 주는 것으로 충분하지 않습니다. 모델이 무엇을 요약하고, 어떤 형식으로 응답해야 하는지 명확히 인식하게 만드는 방식이 바로 프롬프트 엔지니어링입니다. 이는 입법 문서처럼 구조적이고 난해한 텍스트를 다룰 때 더욱 중요합니다.
BillSum을 활용한 요약 학습에서는 다음과 같은 방식으로 프롬프트를 설계합니다:
- 역할 명확화: 모델에게 "이 문서를 요약하라"는 지시만 주는 것이 아니라, 어떤 항목(목표, 조항, 영향 등)을 중심으로 요약해야 하는지를 구체적으로 알려줍니다.
- "다음 미국 의회 법안의 주요 목적과 기대 결과, 그리고 중요한 수정사항을 요약하세요."
- "이 법안을 다섯 문장 이내로 요약하되, 핵심 목표와 명령 사항만 포함시키세요."
- 예시:
- 언어 수준 조정: 법률 용어에 익숙하지 않은 사용자도 이해할 수 있도록, 평이한 언어로 요약하라는 프롬프트를 설계합니다.
- "이 법안의 핵심 내용을 쉽게 설명해주세요. 누가 영향을 받는지, 어떤 자금이 쓰이는지 포함해주세요."
- 예시:
- 구조화된 응답 유도: 요약이 중구난방이 되지 않도록, 응답 내 구조나 순서를 명시해주면 모델이 일관성 있게 결과를 생성할 수 있습니다.
프롬프트 엔지니어링은 단순한 입력 기술을 넘어, LLM의 추론 방향을 유도하는 **‘문제 설정의 기술’**이라 볼 수 있으며, 요약 품질을 크게 좌우하는 결정적 요소로 작동합니다.
🎯 4. 파인튜닝 후 기대되는 모델 성능
LLM을 BillSum 데이터셋에 기반해 정밀하게 파인튜닝하고 나면, 모델은 단순한 문장 압축 기능을 넘어서 정치적·법률적 맥락에 기반한 요약 능력을 보여주게 됩니다. 구체적으로는 다음과 같은 성능 향상이 기대됩니다.
● 법안 요약의 정확성과 일관성 향상
- 모델은 각 법안의 주요 목적, 조항, 시행 주체, 영향 대상을 정확히 식별하고, 이를 짧고 명확한 요약문으로 재구성합니다.
- 예를 들어 환경 규제 법안을 요약할 경우, “어떤 오염물질을 규제하고”, “어떤 기관이 집행하며”, “어떤 벌칙이 주어지는가”까지 포함한 요약이 가능합니다.
● 새로운 입법 문서에 대한 일반화 능력
- 학습에 사용되지 않은 캘리포니아 주 법안에도 효과적으로 대응하며, 언어 표현이나 구조가 달라져도 핵심 내용을 요약할 수 있는 범용성 있는 처리 능력을 획득합니다.
● 요약문의 구조적 명료성과 접근성 확보
- 요약문은 전문가뿐 아니라 일반 대중도 이해할 수 있도록, 불필요한 법률 용어를 줄이고 핵심만 담은 설명으로 구성됩니다.
- 특히 “누가 영향을 받는가”, “기존 제도에서 무엇이 바뀌는가”, “얼마나 큰 예산이 투입되는가” 같은 실질적 정보가 포함되어 정책 커뮤니케이션의 도구로도 기능할 수 있습니다.
결과적으로, 파인튜닝된 LLM은 정치학자가 수백 페이지짜리 법안을 검토하는 시간을 획기적으로 줄여주고, 입법 분석의 자동화 수준을 새로운 차원으로 끌어올릴 수 있습니다. 이는 의회 연구실, 시민단체, 정책 싱크탱크는 물론, 일반 시민의 정보 접근성 향상에도 기여합니다.
🔍 5.4 LLM 추론: 제로샷 학습(Zero-Shot In-Context Learning)의 실천
LLM의 가장 혁신적인 활용 방식 중 하나는 Zero-Shot Learning(ZSL), 즉 사전 학습만으로도 새로운 작업을 수행할 수 있는 능력입니다. 이 방식은 별도의 추가 훈련이나 라벨링 데이터 없이도 정치적 문장을 분석할 수 있어, 데이터가 부족한 현실의 정치학 연구 환경에서 특히 유용합니다.
🧠 제로샷 학습(ZSL)의 개요
Zero-Shot Learning이란, LLM이 사전 학습(pretraining)만으로 특정 작업을 수행하는 것을 의미합니다. 예를 들어 감정 분석, 입장 분류, 이념적 스펙트럼 판별 같은 작업을 위해 별도의 task-specific 학습 없이도 모델이 정답에 가까운 예측을 내놓을 수 있습니다.
정치 데이터는 라벨링이 매우 어렵고 민감한 특성을 지니기 때문에, ZSL은 컴퓨팅 정치학(computational political science)에서 매우 유망한 접근법입니다. LLM은 이미 대규모의 일반 텍스트를 학습했기 때문에, 정치적 표현과 맥락을 상당히 높은 수준으로 이해하고 있습니다. 따라서 **라벨이 없는 원시 텍스트(raw text)**에도 정교하게 반응할 수 있습니다.
🧰 태스크 지향형 프롬프트 설계: 모델에게 ‘정확한 질문’을 던지는 기술
제로샷 학습(Zero-Shot Learning)의 핵심은 모델에게 "무엇을 하라는지" 정확히 알려주는 것입니다. 훈련된 데이터가 없이도 작업을 수행하려면, LLM이 따라야 할 **명확하고 구조화된 지시(prompt)**가 반드시 필요합니다. 이를 태스크 지향형 프롬프트 설계라고 부릅니다.
예를 들어, 미국 대선과 관련된 감정 분석 작업을 하고 싶다면 단순히 “이 문장을 분석해줘”라고 묻는 것만으로는 부족합니다. 모델이 해야 할 작업, 출력 포맷, 분류 범주까지 모두 구체적으로 제시해야 더 정확한 응답을 얻을 수 있습니다.
실제 프롬프트 예시는 다음과 같습니다.
Prompt 예시
“아래의 문장이 대통령 선거와 관련하여 어떤 감정(sentiment)을 담고 있는지 분석하시오. 감정은 Positive, Negative, Neutral 중 하나로 분류하시오.”“Despite the turbulent political climate, Candidate X has shown strong leadership qualities and promises substantial reforms that could benefit the economy.”
이 경우 모델은 문장에서 “strong leadership”과 “substantial reforms”라는 긍정적 표현에 주목해, Positive라는 응답을 도출하게 됩니다.
이처럼 프롬프트는 단지 질문이 아니라 모델에게 제공하는 문제 해결 프레임입니다. 따라서 감정 분석 외에도 입장 분류, 정책 분류, 이념 스케일링 등 다양한 정치학 작업에 맞는 프롬프트를 구체적으로 설계할 수 있습니다.
🧩 프롬프트에 맥락 포함하기: 정치는 ‘언제 누가 말했는지’가 중요하다
정치적 발언은 항상 **맥락(Context)**에 따라 의미가 달라집니다. 같은 문장도 그 문장이 발언된 시점, 발언자, 정책 이슈, 정당적 배경에 따라 감정이나 입장이 달라질 수 있습니다.
따라서 제로샷 학습에서 프롬프트에 해당 발언의 정치적 맥락을 함께 제공해주면, 모델이 훨씬 정확하고 세밀하게 판단할 수 있습니다.
예를 들어:
Prompt 예시 (맥락 포함)
“다음 발언은 최근 이민정책에 대한 대선 후보 토론 중 발언된 문장입니다. 감정 분석을 수행하시오. 결과는 Positive, Negative, Neutral 중에서 선택하시오.”“Candidate Z wants open borders, which would be a disaster for national security.”
이 프롬프트는 단지 문장만 제시하는 것이 아니라, 이 문장이 “이민 정책”과 관련된 토론 중 나온 것임을 명시하고 있습니다. 이로써 모델은 단어 자체뿐 아니라 발언 맥락에서 오는 부정적 감정 흐름도 포착할 수 있게 됩니다.
또한 다음과 같은 맥락도 유용합니다:
- 발언자의 정당 또는 이념적 성향
- 발언 시점 (예: 대선 직전, 위기 상황 중 등)
- 이슈 영역 (예: 건강보험, 환경, 총기 규제 등)
- 발언 대상 (예: 유권자, 상대 후보, 정책 등)
이처럼 정치 텍스트는 발언의 배경이 반영되지 않으면 오해의 소지가 크기 때문에, 프롬프트 설계 시 이런 정보를 함께 구조화해주는 것이 ZSL 정확도를 높이는 핵심 전략입니다.
요약하자면,
- 태스크 지향형 프롬프트는 정치 텍스트 분석의 목적과 방식, 분류 기준을 명확히 전달하고,
- 맥락 포함 프롬프트는 발언의 시기, 이슈, 정치적 상황 등 추가 정보를 담아 해석 정확도를 높이는 방식입니다.
두 접근 모두 정치학에서 LLM을 실질적으로 활용하려면 반드시 고려해야 할 핵심 기법입니다.
🧪 정치학에서 ZSL의 활용 예
ZSL은 감정 분석을 넘어 다양한 정치학 작업에 유용하게 적용됩니다.
- 입장 분류(Stance classification): 발언이 찬성인지 반대인지 분류
- 이념 분류(Ideological Scaling): 보수-진보 구분, 극단성 척도 부여
- 정책 카테고리 분류: 문장이 어떤 정책 영역(복지, 국방, 환경 등)에 속하는지 식별
이러한 작업은 기존에는 다량의 라벨링 데이터를 필요로 했지만, ZSL은 이를 신속하고 비용 효율적으로 처리할 수 있습니다.
🗳 실제 사례: 2024년 미국 대선 감정 분석
실제 연구에서는 Llama2와 같은 LLM을 활용하여, 미국 대선과 관련된 뉴스 기사, 토론 발언, SNS 포스트에 대해 감정 분석을 실시했습니다. 아래는 그 예시입니다.
Prompt: Evaluate the sentiment in the following statement about the presidential election (Positive, Negative, or Neutral).
Text: "The recent tax proposal from Candidate X is likely to hurt middle-class families while favoring large corporations."
LLM Response: Negative Explanation: “hurt middle-class families”, “favoring large corporations” 같은 부정적 단어가 정책에 대한 불만을 나타냄.
이와 같은 방식으로, 제로샷 감정 분석은 선거 국면에서 후보자별 여론의 정성적 흐름을 신속하게 파악할 수 있는 수단이 됩니다.
✅ 요약
- Zero-Shot Learning은 라벨링 없이도 LLM이 정치 데이터를 분석할 수 있게 해줌
- 프롬프트 설계와 맥락 정보의 포함이 성공적인 ZSL의 핵심
- 감정 분석뿐 아니라 이념 분석, 정책 분류 등으로도 확장 가능
- 데이터가 부족한 정치 분야에서 탐색적 연구와 실시간 분석에 최적화된 방식
LLM 기반 ZSL은 정치 데이터의 분석 접근성을 획기적으로 높이며, 정치학 연구에서 지식 기반 접근을 넘어, 경험적 분석 능력을 강화하는 핵심 도구로 자리 잡고 있습니다.
🧠 5.5 소수 예시 학습 (Few-Shot In-Context Learning): 적은 예시로도 강력한 추론을 이끌어내는 방법
LLM을 활용한 정치 분석에서 Few-Shot Learning은 매우 유용한 접근입니다. 특히 주석 데이터(annotation)가 부족하거나 민감한 정치 이슈에 대해 대규모 데이터셋을 수집하기 어려운 경우, 이 방식은 모델에게 몇 가지 예시만 보여주고도 새로운 문제를 푸는 데 활용됩니다.
🧩 Few-Shot Learning이란?
Few-shot learning은 소량의 예시만 가지고도 LLM에게 새로운 작업을 수행하게 하는 문맥 기반 학습(in-context learning) 기법입니다. 모델 전체를 다시 훈련(fine-tune)하지 않고도, 몇 가지 샘플만 잘 보여주면 모델이 "아, 이런 식으로 하면 되는구나" 하고 패턴을 파악해 작업을 수행할 수 있게 됩니다.
예를 들어, 뉴스 제목이 주어졌을 때 그것이 진짜 뉴스인지 가짜 뉴스인지 구분하는 작업을 시킨다고 가정해봅시다. 이때 모델에게 대규모의 라벨링된 데이터를 제공하지 않고, 단지 세네 개 정도의 실전 예시만 보여주면 됩니다. 이 방식은 특히 정치학처럼 라벨링 데이터가 부족한 학문 분야에서 굉장히 유용합니다.
Few-shot learning은 zero-shot 방식(예시 없이 질문만 주는 방식)보다 훨씬 더 높은 정확도를 보여주는 경우가 많으며, 전체 fine-tuning보다 훨씬 저렴하고 빠릅니다. 그래서 최근 정치 데이터 분석, 여론 추정, 가짜 뉴스 탐지와 같은 영역에서 활발히 활용되고 있습니다.
🧰 효과적인 예시 설계: ‘가짜 뉴스 탐지’ 과제를 중심으로
Few-shot 방식의 성패는 결국 **“어떤 예시를 보여주느냐”**에 달려 있습니다. 예시가 직관적이고, 문제의 본질을 잘 반영한다면 모델은 매우 빠르게 패턴을 습득합니다.
여기서는 2024년 미국 대선을 둘러싼 가짜 뉴스 탐지를 예로 들어 봅니다. 정치 뉴스에는 사실과 허위가 혼재되어 있고, 허위 정보는 단순한 거짓말보다는 종종 ‘그럴듯하지만 왜곡된 주장’, ‘감정적으로 과장된 표현’으로 구성되기 때문에 이 복합성을 고려한 예시 구성이 필요합니다.
🔍 예시 프롬프트 설계 예 (Fake News Detection)
“다음 뉴스 헤드라인이 진짜인지 가짜인지 판단하시오.”
예시 1: "Presidential candidate X pledges new economic reforms to boost national job growth and reduce unemployment."
→ 정답: 진짜 (Real)
예시 2: "Urgent: Voting machines in [Swing State] are flipping votes from Candidate X to Candidate Y, claims anonymous election officer."
→ 정답: 가짜 (Fake)
예시 3: "Scientists confirm presidential candidate X is involved in alien cover-up."
→ 정답: 가짜 (Fake)
이렇게 구성된 프롬프트는 모델에게 몇 가지 신호를 줍니다:
- 사실 기반의 경제 공약은 일반적으로 신뢰 가능한 진짜 뉴스로 분류됨
- **무기명 소스(anonymous)**나 선거 조작 주장 등은 검증되지 않은 가짜 뉴스일 가능성 높음
- 외계인 커버업 같은 음모론적 서술은 전형적인 허위 정보 패턴임
예시마다 사실성의 레벨을 다르게 하고, 언어 스타일도 구분하면 모델이 허위 뉴스의 전형적인 패턴을 더 잘 학습합니다. 특히 감성적인 문장, 익명 출처, 음모론적 플레임 등은 가짜 뉴스 탐지의 핵심적 언어적 특징이므로 반드시 반영해야 합니다.
또한 주의할 점은 너무 유사한 예시만 반복하지 말고, 주제의 다양성(경제, 복지, 선거 제도 등)과 허위 정보의 유형 다양성(거짓 주장, 과장, 왜곡 등)을 확보하는 것이 좋습니다.
🔍 프롬프트에 맥락 포함하기: 정치적 민감성 고려
Few-shot learning에서 프롬프트에 ‘맥락’을 얼마나 잘 포함시키느냐는 모델의 판단력에 큰 영향을 줍니다. 특히 정치적 주제를 다룰 때는 맥락의 부재가 곧 오해로 이어질 수 있기 때문에, 반드시 발언의 배경 정보나 출처, 시기, 관련된 사건 등을 함께 제시해야 합니다.
예를 들어, 다음과 같은 문장이 있다고 가정해 봅시다.
"우리는 더 이상 불법 이민자들에게 세금을 낭비하지 않을 것이다."
이 문장만 보면 긍정인지 부정인지, 혹은 진짜인지 가짜인지 단정하기 어렵습니다. 그러나 이 문장이 ❶ 누가 말했는지, ❷ 어느 시점에서 나왔는지, ❸ 어떤 맥락에서 언급되었는지를 함께 주면 완전히 다르게 해석됩니다.
🧭 맥락 포함 프롬프트 예시
문장: “우리는 더 이상 불법 이민자들에게 세금을 낭비하지 않을 것이다.”
상황 설명: 이 문장은 2024년 미국 대선 토론에서 공화당 후보 X가 발언한 것이다.
해당 후보는 강경한 이민정책을 지지하고 있으며, 당시 이민자에 대한 복지 지원 축소를 주장하고 있었다.
질문: 이 발언은 긍정적, 부정적, 중립 중 어느 감정에 가까운가?
이처럼 정치적 발언의 화자, 시기, 맥락을 명시해 주면 LLM은 해당 문장의 감정, 진위, 입장 등을 훨씬 정확히 판별할 수 있습니다.
또한 가짜 뉴스 탐지 과제에서는 출처의 신뢰도도 맥락의 핵심 요소입니다. 예컨대 아래 두 문장을 비교해보면:
- "CNN은 조기 투표율이 역대 최고치를 기록했다고 보도했다."
- "익명의 TikTok 사용자가 투표 조작을 주장했다."
내용 자체보다도 출처의 신뢰도가 모델 판단에 핵심적인 단서가 될 수 있습니다. 따라서 프롬프트 안에 언론사, SNS 플랫폼, 익명 여부 등도 함께 삽입하면 좋습니다.
⚖️ 프롬프트 길이와 예시 다양성: 균형이 중요하다
Few-shot learning에서 가장 어려운 점 중 하나는 바로 프롬프트 길이와 예시 수의 균형을 잡는 일입니다. 모델에 더 많은 예시를 주면 당연히 정확도는 올라가지만, 동시에 입력이 길어지고 문맥이 복잡해져 오히려 혼란을 초래할 수도 있습니다.
또한 LLM은 길이가 제한된 입력 창(context window)을 갖고 있기 때문에 너무 많은 예시를 포함하면 실제 테스트 문장이 잘리지 않도록 주의해야 합니다.
🧮 적정 예시 수는?
대부분의 작업에서 3~5개의 예시가 이상적이라고 알려져 있습니다. 특히 정치적 주제에서 가짜 뉴스 탐지처럼 문맥에 따라 판단이 갈릴 수 있는 복잡한 작업일수록, 3~4개의 질적으로 다양한 예시를 주는 것이 효과적입니다.
- 예시가 너무 적으면: 모델이 일반화에 실패하고 편향된 판단을 내릴 수 있음
- 예시가 너무 많으면: 모델이 중간에 집중력을 잃거나 최신 예시만 반영함
🌐 예시의 다양성도 중요하다
프롬프트 안의 예시들은 주제, 어조, 형식, 표현 방식 면에서 다양해야 합니다. 예를 들어, 모두 경제 관련 가짜 뉴스만 제시하면, 모델은 정치/사회/복지 주제를 만나면 오작동할 수 있습니다.
좋은 예시 구성이란?
- 주제 다양성: 선거, 세금, 복지, 외교, 이민 등 다양한 정치 이슈 포함
- 정보 유형 다양성: 진술, 뉴스 제목, SNS 게시글 등 형식의 다양성 확보
- 가짜 뉴스 유형 다양성: 과장, 날조, 잘못된 인용, 음모론 등 다양한 오류 형태 제시
이렇게 프롬프트를 짧고 명료하게 유지하면서도 내용은 다양하게 구성하는 것이 few-shot 학습의 효과를 극대화하는 방법입니다.
.
🧠 LLM 추론을 보완하는 고급 기법들
정치학적 분석에서 LLM을 사용할 때 단순한 텍스트 생성만으로는 충분하지 않은 경우가 많습니다. 정보의 정확성, 시의성, 추론의 일관성, 지식 업데이트 가능성까지 고려해야 합니다. 이러한 한계를 보완해주는 네 가지 주요 기술이 바로 아래와 같습니다.
🔎 RAG (Retrieval-Augmented Generation): 외부 지식으로 정확도 보완하기
📌 기본 개념
RAG는 Retrieval-Augmented Generation의 약자로, 기존의 LLM이 가진 한계를 보완하기 위해 등장한 기술입니다. 일반적인 LLM은 학습 당시의 정적인 데이터만을 바탕으로 응답을 생성합니다. 하지만 현실의 정치 환경은 매우 빠르게 변화하며, 정책, 여론, 선거 결과 등은 실시간으로 바뀝니다. 이런 정보는 사전 학습 모델 안에 존재하지 않을 수 있고, 그로 인해 낡거나 부정확한 답변이 생성될 수 있습니다.
RAG는 이런 한계를 극복하기 위해 다음과 같은 방식으로 작동합니다:
- Retriever 모듈이 사용자의 질문과 관련된 정보를 외부 데이터베이스(예: 문서 저장소, 뉴스, 정책 데이터베이스 등)에서 실시간으로 검색합니다.
- Generator는 검색된 문서를 입력받아, 이를 바탕으로 보다 정확하고 현실에 맞는 응답을 생성합니다.
즉, 단순히 모델 안에 저장된 정보가 아니라, 외부에서 실시간으로 찾아온 정보를 바탕으로 답변을 만들어낸다는 점에서 기존 방식과 차별화됩니다.
🗳 정치학 분야에서의 활용 예시
🗳️ 예시 1: 대선 여론조사 실시간 분석
질문: "2024년 미국 대선에서 펜실베이니아주의 최신 여론조사 결과는?"
기존 LLM만으로는 이 질문에 정확히 답하기 어렵습니다. 모델이 마지막으로 학습한 데이터가 오래되었을 수 있기 때문입니다.
RAG 시스템은 다음과 같이 작동합니다.
- Retriever가 갤럽(Gallup), 퓨 리서치(Pew Research), 뉴욕타임스 등 신뢰할 수 있는 여론조사 기관의 최신 데이터를 찾아냅니다.
- 해당 데이터(예: “Candidate A: 48%, Candidate B: 46%”)를 문맥으로 삽입합니다.
- Generator가 이 정보를 요약하여 “펜실베이니아에서는 A 후보가 소폭 앞서고 있으며, 최근 조사에서는 지지율 변동이 크다”는 식의 응답을 생성합니다.
이렇게 생성된 답변은 사실 기반, 최신성 확보, 정치적 맥락 반영이라는 세 가지 조건을 충족시킵니다.
🏛️ 예시 2: 입법 추적과 정책 요약
질문: “최근 통과된 환경 관련 법안은 어떤 내용을 담고 있나요?”
- Retriever가 의회 기록이나 입법 데이터베이스에서 가장 최근에 통과된 환경 관련 법안의 전문 및 요약을 검색합니다.
- Generator가 해당 내용을 바탕으로, 해당 법안의 목적, 주요 조항, 영향을 받는 이해당사자 등을 요약합니다.
이는 연구자에게 빠르고 정확한 입법 정보 접근을 가능하게 하며, 공공 커뮤니케이션에서도 유용하게 활용됩니다.
🧠 기술적 이점
| 정확도 향상 | 외부 정보에 기반하므로 구체적이고 사실적인 응답 생성 가능 |
| 최신성 확보 | 사전 학습 시점 이후의 데이터도 반영 가능 |
| 해석 가능성 | 답변에 사용된 자료 출처를 추적하거나 인용 가능 |
| 정치적 유용성 | 여론조사, 입법, 선거정보 등 정치 도메인에서 요구되는 정보 반응성 충족 |
[질문 입력]
↓
[Retriever: 외부 지식 검색]
↓
[Context 생성: 관련 문서 요약]
↓
[Generator: 답변 생성]
예:
입력 질문: “2024년 대선 지지율이 가장 많이 변화한 주는 어디인가요?”
검색된 정보: “미시간, 펜실베이니아에서 최근 2주간 지지율 격차 5% 이상 변동”
생성 응답: “최근 2주간 펜실베이니아와 미시간에서 후보 간 지지율 변화가 컸으며, 특히 무당층의 이동이 주요 원인으로 보입니다.”
🧠 2. Chain-of-Thought Reasoning (CoT): 다단계 논리 추론 구현하기
📌 기본 개념
**Chain-of-Thought Reasoning (CoT)**은 말 그대로 "사고의 흐름을 따라가는 방식"입니다. 일반적인 LLM은 사용자의 질문에 대해 단번에 정답을 출력하려고 합니다. 하지만 정치학과 같은 복잡한 분야에서는 단일 응답보다, 그 응답에 이르게 되는 사고 경로 자체가 더 중요하고 유익할 수 있습니다.
CoT는 LLM이 문제 해결 과정에서 중간 단계의 논리적 추론을 명시적으로 수행하도록 유도합니다. 즉, 질문에 대해 곧바로 정답을 내기보다는, 몇 단계의 논리적 reasoning 과정을 거치게 합니다. 이는 마치 사람이 문제를 해결할 때 중간 계산이나 근거를 종이에 적으며 사고하는 방식과 유사합니다.
🏛 정치학적 맥락에서의 필요성
정치학 문제는 단순한 사실 질문이 아니라 다차원적 요소들이 상호작용하는 복합적 질문이 많습니다.
예를 들어 다음과 같은 질문을 생각해봅시다.
"이민 개혁 정책에 대한 미국 대중의 여론은 어떻게 형성되며, 향후 지지율에 어떤 영향을 줄까?"
이 질문은 단순한 답변이 아닌 다음과 같은 여러 요소의 분석을 요구합니다.
- 과거의 유사 정책에 대한 반응
- 특정 인구 집단(예: 저학력 백인, 히스패닉 유권자 등)의 태도 변화
- 최근의 경제 지표와 실업률
- 정당별 정치 프레임과 미디어의 역할
- SNS와 여론조사의 시계열 데이터
CoT는 이처럼 복합적인 질문을 해결할 수 있도록 LLM에게 “순차적 사고과정”을 학습시키고 응답하도록 유도합니다.
🔄 예시: 이민 개혁 정책에 대한 여론 예측
🎯 목표:
이민 개혁에 대한 미국 대중의 지지/반대 수준을 예측하고 그 배경을 설명
🧠 CoT 추론 흐름:
- 과거 맥락 파악
“2013년과 2018년에도 유사한 이민 개혁 법안이 논의되었고, 당시 대중 여론은 정치 성향에 따라 뚜렷한 차이를 보였다. 특히 공화당 지지층은 부정적이었으며, 민주당 지지층은 긍정적이었다.” - 사회·인구학적 변화 분석
“최근 몇 년 사이 남부주에서 히스패닉 유권자의 비중이 증가하였고, 이는 정책 수용성에 영향을 미칠 수 있다.” - 경제적 고려
“팬데믹 이후 특정 산업에서 노동력 부족이 이민자 유입 필요성에 대한 긍정적 인식을 강화하고 있다.” - 현재 여론 동향 파악
“최근 갤럽과 Pew 조사에서는 전체적으로 찬성 비율이 52%로 나타났으며, 특히 청년층(18–29세)에서는 67%가 찬성한다고 응답했다.” - 예측과 결론 도출
“이러한 요소를 종합할 때, 단기적으로는 지지율 상승이 예상되며, 특히 도시 지역과 고학력 유권자 중심으로 긍정적 여론이 확산될 가능성이 높다.”
이처럼 CoT는 단순히 “지지율이 올라간다”는 결론을 내는 것이 아니라, 그 과정을 논리적이고 구조적으로 설명해주기 때문에 분석 신뢰성과 해석 가능성이 매우 높습니다.
📚 정치학 분야에서의 활용 예시
| 여론 형성 분석 | 여러 인과요소(정당 태도, 경제 지표, 언론 프레임 등)를 단계별로 추론하여 결론 도출 |
| 정책 영향 예측 | 새로운 법안 도입 시 정책 수혜 집단과 반대 집단을 나누어 단계적으로 분석 |
| 국제관계 이슈 해석 | 국가 간 갈등의 역사적 배경, 외교 입장, 안보 연합 등을 체계적으로 따져봄 |
| 이데올로기 분류 | 텍스트 내 정치적 단어, 표현, 서사 구조를 계층적으로 분석해 이념적 성향 추론 |
🧠 CoT의 장점
- 복합적인 문제를 다층적으로 해석할 수 있음
- 모델의 해석 가능성과 투명성 향상
- 정치학적 타당성 있는 근거 기반 분석 가능
- 모델의 일관성과 신뢰도 증가 (단순 암기식 답변을 피함)
🧾 3. Knowledge Editing: LLM 내부 지식의 국소적 업데이트
Knowledge Editing은 모델 전체를 재학습하지 않고, 특정 지식 노드만을 수정하여 최신 정보를 반영할 수 있도록 하는 기법입니다. 정치 분야는 특히 정보가 빠르게 바뀌기 때문에 매우 유용합니다.
적용 예시:
- 기후 정책 목표 변경: “2035년까지 온실가스 40% 감축” → “2040년까지 50% 감축”
- 주요 법안 통과 여부 갱신
- 특정 정치인의 직위 변경 반영
Knowledge Editing을 통해, LLM이 과거 사실을 반복하거나 잘못된 정보를 그대로 유지하는 문제를 해결할 수 있습니다. 이렇게 하면 분석 도구로서의 신뢰성과 적시성이 높아집니다.
🔁 4. Self-Consistency Decoding: 답변 일관성 확보
LLM은 동일한 질문에도 매번 다른 응답을 낼 수 있습니다. Self-Consistency Decoding은 이를 개선하기 위한 기법입니다.
- 동일한 질문을 다양한 표현이나 순서로 여러 번 모델에 제시합니다.
- 생성된 다양한 응답 중에서 가장 많이 등장하거나 일관된 내용을 최종 결과로 선택합니다.
예시: 이민 정책에 대한 감정 분석
- 다양한 프롬프트 버전을 활용해 LLM이 생성한 응답 수집
- “부정적”이 가장 많이 등장했다면, 해당 발언의 주된 정서로 간주
정치적 주제는 감정과 해석이 엇갈릴 수 있기 때문에, 이 방식은 중립적이고 신뢰할 수 있는 응답을 생성하는 데 유리합니다. 특히 논쟁적 이슈나 여론 조사 해석에 적합합니다.
📌 정리
| RAG | 외부 지식 검색 후 응답 생성 | 실시간 여론조사, 정책 변경 반영 |
| CoT | 단계별 추론 흐름 제시 | 복합 정책 분석, 여론 동향 예측 |
| Knowledge Editing | 특정 지식 노드 업데이트 | 정책 변화, 직책 수정, 최신 정보 반영 |
| Self-Consistency Decoding | 응답의 일관성 확보 | 감정 분석, 여론 추정, 정책 해석 안정화 |
이러한 고급 보조 기술을 적절히 활용하면, LLM은 정치학 연구에서 단순한 요약기나 분류기를 넘어서 정교한 추론 파트너로 거듭날 수 있습니다. 특히 실시간성과 신뢰성이 중요한 현대 정치 분석에서는 이 네 가지 기법이 핵심 역할을 하게 됩니다.
📊 5.7 LLM을 활용한 유권자 시뮬레이션: 정치 편향과 특성 생성 능력 분석
LLM이 실제 정치 연구에 얼마나 쓸모 있는 도구가 될 수 있는지 보여주는 중요한 사례로, 연구팀은 미국 정치 연구에서 가장 널리 쓰이는 ANES 2016 데이터를 바탕으로 LLM이 유권자처럼 투표 결정을 내릴 수 있는지를 실험했습니다. 또한, 투표 결정에 필요한 "정치 이념" 같은 변수를 모델이 얼마나 잘 생성할 수 있는지도 함께 살펴봤습니다.
⚙️ 실험 환경: 모델, 하드웨어, 데이터
실험에 사용된 모델은 총 네 가지입니다.
- GPT-4o (상용, 대형 모델)
- GPT-4o-mini (상용, 소형 모델)
- Llama 3.1 8B (오픈소스, 중형 모델)
- Llama 3.1 70B (오픈소스, 대형 모델)
하드웨어는 고사양 GPU 클러스터로 구성되었고, 모든 모델에 대해 계산 자원을 최적화했습니다. 실험에 사용된 데이터는 ANES 2016 타임 시리즈 데이터로, 유권자의 인구통계, 정치성향, 종교 등 다양한 속성이 포함되어 있어 시뮬레이션과 특성 생성 모두에 이상적인 조건을 제공합니다.
🧪 실험 설계: LLM이 유권자처럼 행동할 수 있을까?
연구진은 각 LLM에게 유권자 페르소나(persona)를 부여했습니다. 이 페르소나는 성별, 인종, 교육 수준, 종교, 정치 성향 등의 정보로 구성되며, 각 LLM은 이 정보를 바탕으로 선거에서 어느 후보를 선택할지 결정하게 됩니다.
실험은 두 가지 방식으로 구성됨:
- 기본 시나리오(base): ANES에서 제공된 원래의 정치 성향 데이터를 그대로 사용해 투표를 시뮬레이션합니다.
- 생성 시나리오(gen): 정치 성향을 ANES 원본 대신, LLM이 인구통계 정보를 보고 직접 생성하게 한 후, 이 생성된 성향을 기반으로 투표 선택을 하게 합니다. 이때는 Chain-of-Thought (CoT) 기법을 사용하여 논리적 단계로 답변을 유도합니다.
🔍 예시 프롬프트
Step 1: 정치 성향 생성
당신은 [demographics]을 가진 사람입니다. 현재 연도는 [2016]입니다. 두 정당의 정책은 다음과 같습니다: [두 당의 정책 비교]. 이 정보를 바탕으로, 당신은 어느 쪽에 더 가깝습니까?
- 매우 진보적
- 다소 진보적
- 중도
- 다소 보수적
- 매우 보수적
Step 2: 투표 결정
당신은 [위와 같은 demographic 정보 + 생성된 정치 성향]을 가지고 있습니다. 후보자 정보는 다음과 같습니다: [클린턴, 트럼프의 이력]. 오늘 선거가 있다면 누구에게 투표하겠습니까?
- 민주당 (힐러리 클린턴)
- 공화당 (도널드 트럼프)
- 선택 없음
📈 평가 기준
- 정치 편향 평가:
- 투표 결과에서 공화당/민주당 선택 비율(R)을 계산해 실제 ANES 결과(47.7%)와 얼마나 가까운지 비교함
- 예: R = 공화당 투표 수 / (공화당 + 민주당 투표 수)
- 정치 특성 생성 품질:
- LLM이 생성한 정치 성향과 ANES 원본의 정치 성향을 비교
- x축: ANES 실제 성향 (1 = 매우 진보적, 7 = 매우 보수적)
- y축: 모델이 생성한 성향
- 점들이 대각선에 가까울수록 정확도 높음
🧾 주요 결과
- GPT-4o, Llama 3.1-70B는 실제 ANES 결과와 가장 잘 일치함 (47.67%, 47.79%)
- **정치 성향 데이터가 제거된 GPT-4o(NP)**는 트럼프에게 편향된 결과를 보임 (70.26%) → 이는 정치적 특성 변수의 제거가 편향을 심화시킨다는 증거
- Llama 3.1-8B는 전반적으로 공화당 응답을 회피하고 민주당 성향으로 기울어짐
- GPT-4o-mini, Llama 3.1-8B는 특성 생성에서도 낮은 정확도를 보임 → 적은 파라미터 수와 관계 있음
🧩 데이터셋의 함정도 드러남
- 일부 응답자는 자기는 "매우 진보적"이라고 했지만 실제로는 "공화당 지지자"로 분류됨
- 이런 모순된 클러스터가 데이터 자체의 잠재적 문제를 드러냄 → 모델의 정확도만의 문제가 아님
🧠 요약: 이 사례연구가 주는 함의
- LLM이 단순히 데이터에 반응하는 것을 넘어, 정치적 맥락을 생성하고 해석할 수 있는 능력이 있음을 입증
- 모델 크기, CoT 설계, 정치 특성의 활용 여부가 예측의 정확도와 편향에 큰 영향을 미침
- 정제된 데이터와 정확한 프롬프트 설계 없이는 LLM도 정치 편향을 증폭시킬 수 있음
- 따라서 LLM을 정치 연구에 활용할 때는 생성된 특성과 결과에 대한 정밀 검증이 필수임